
On 29/08/13 12:28 AM, "Adam Armstrong" adama@memetic.org wrote:
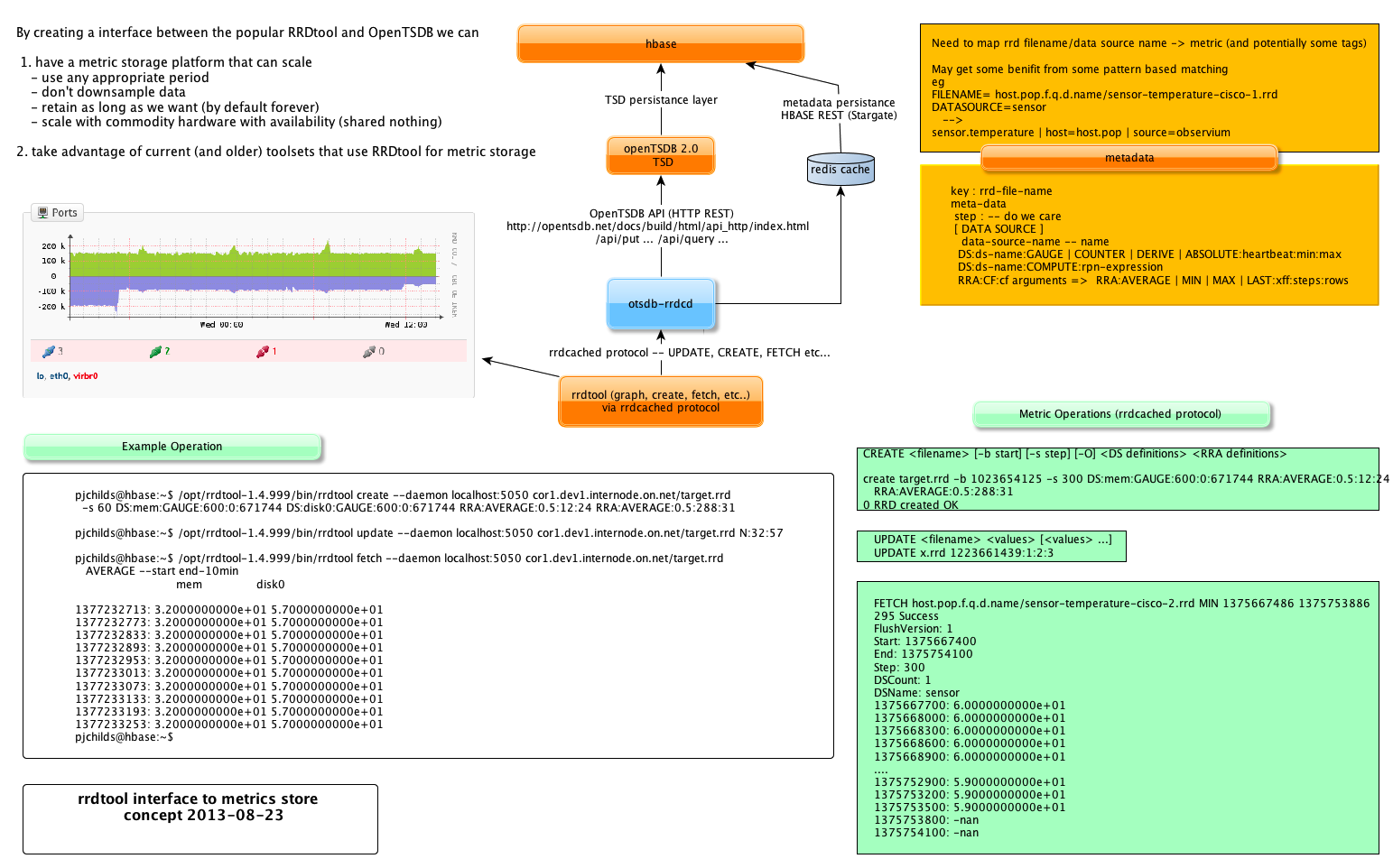
I have some proof-of-concept code that talks 'rrdcached' protocol for CREATE/UPDATE/FETCH and persists the data into OpenTSDB which is ontop of a hbase cluster, so can scale pretty much horizontally (ie more nodes=more metrics).
Well, that sounds interesting.
How does it work, exactly?
Does rrdtool get/give the data to the "cache", and never look at the disk?
How does the single-node performance compare to rrd?
adam.
Attached my 'concept' diagram. Current rrdtool versions can put 'CREATE' and 'UPDATE' messages via rrdcached (or in this case, a replacement) .. 'trunk' versions have 'FETCH' enabled.
Currently the 'concept' code (which is pretty terrible) can do a simple rrdtool create, update, and fetch, and never touches local disk.
I sort of assume that a single node of this would suck vs rrd storage tuned on disk. I need to create some 'real-world' scenarios and perform some appropriate benchmarking.
Here is an interesting talk from the guys @ box regarding their usage of OpenTSDB, with over 350,000/sec avg updates peaking to 1m/s. I assume they size the metric cluster to suite.
http://www.cloudera.com/content/cloudera/en/resources/library/hbasecon/hbas econ-2013-opentsdb-at-box-video.html
Will have a bit more of a fiddle...
My 'target' is a service provider network with over 3000 active network elements (not going to count the servers), which currently has multiple metric collection/display systems (think cacti, customised mrtg, cricket, collectd) none of which can handle all the elements, and most which do not gather the comprehensive metrics set that observium currently does out-of-the-box.
{kind=link}