
Yeah, that's somewhat common when Adam doesn't like something.
Or possibly it was another developer who is now enrolled in the same attitude/culture.
However, while I am critical of how requests like this are handled, and customer engagement (or the lack thereof) more generally; they have started to add a better way of handling this kind of situation recently.
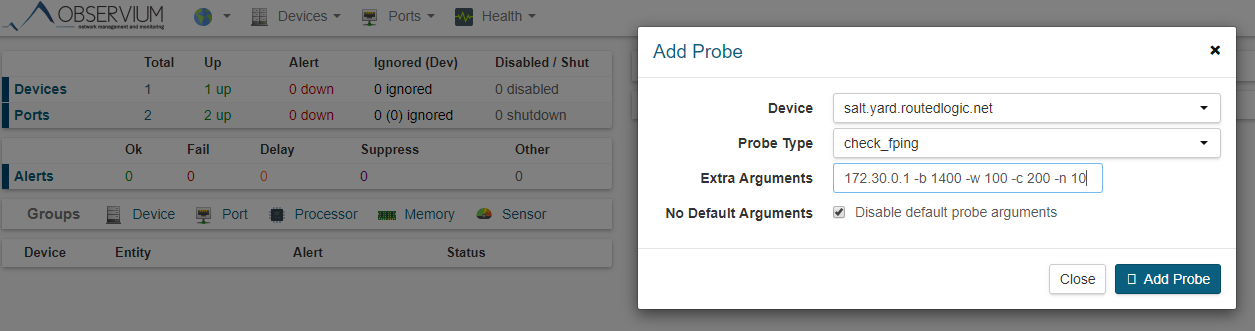
They've added a feature to utilise Nagios probes, and while you do need to associate the probe config to an existing host in Observium for alert association purposes, you can override and pass whatever arguments you want to the probe.
This allows you to monitor other hosts in your network using methods and protocols that would otherwise not be supported by Observium's core code without major modifications. It also means you can easily develop your own probes to meet more bespoke requirements quite easily.
We're yet to test and use it properly, but it's looking like it's going to be a good move.
There still does not appear to be any documentation yet though, from my quick check right now.
So you'll likely need to read the code to understand how to use it at present.
JIRA tickets are likely your other best source of info, I had to log one to fix adding a second probe awhile ago: https://jira.observium.org/browse/OBS-3113?jql=text%20~%20%22probes%22
I'm guessing it's in Professional only at this point, but I havn't checked the community code so perhaps it's there too.
e.g. using check_fping to monitor a router by IP,
[image: obs_probe_menu.png]
[image: obs_probes.png]
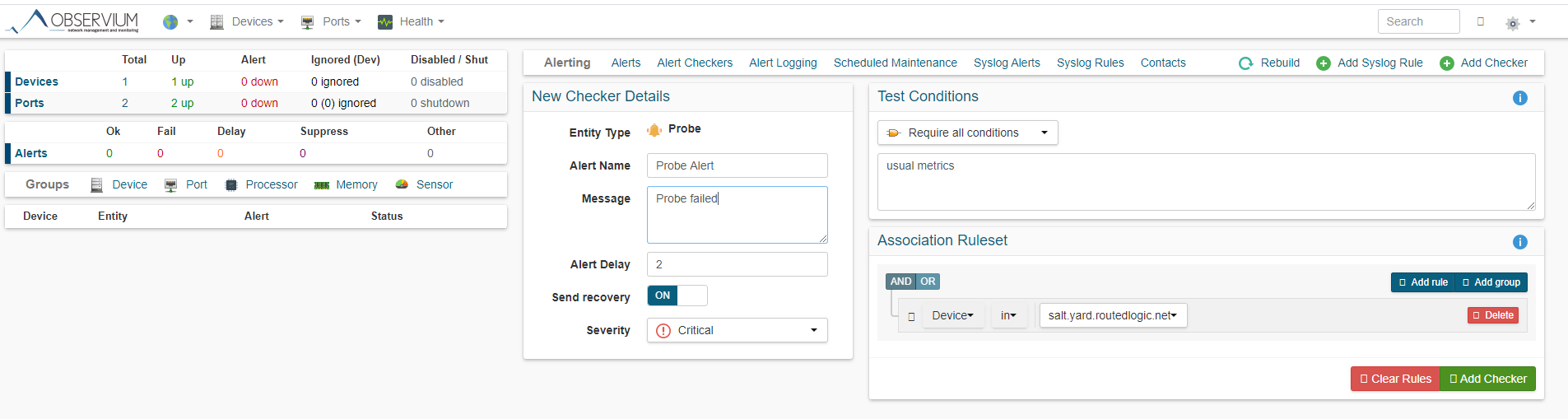
It appears as though alerting may now exist for this too.
And contrary to screenshot below, from the look of the code the metrics seem to be based on KVP's that the nagios plugin returns, which makes sense.
First scan of that code suggests that they won't be accessible though.
[image: obs_probe_alerts.png]
On Fri, 14 Feb 2020 at 06:48, Aaron Finney aaron.finney@openx.com wrote:
This issue appears to have been deleted from Jira. It also appears that multiple people are asking for this feature, which does exist on other platforms, and are all bring told that it's a stupid request.
Add me to the chorus of those who would benefit from this feature:
- We want to use Observium as *the* platform for our corporate IT
team to see the status of our environment, and to generate appropriate alerts 2. We have aggressively moved away from FTEs for our corporate IT staff, and need to provide a simplified environment that a rotating group of MSP-provided technicians can easily ramp up to and work with. We believe Observium fits this use case perfectly. 3. There is a logical flow to this request:
- Observium is our sole monitoring and alerting platform for our entire corporate office infrastructure 2. Observium can only alert on metrics/events for devices 3. We have multiple SaaS partners we connect with over VPN with that we want to monitor for basic reachability, and alert if it's down or latency is high 4. The VPN tunnels between us and our SaaS partners terminate in Google Cloud, so IPSLA is not an option 5. Therefore, the logical conclusion is that if we want to receive alerts when an endpoint on the far side of a VPN tunnel is not reachable, we need it to be a device in Observium that uses ping only to determine up/down/latency
I appreciate that people have a wide range of approaches to this issue, including third-party applications running via cron with sendmail for alerts, but this is antithetical to how our IT landscape is changing. We just moved > 16k physical servers worth of compute, 7PB of storage, and multiple terabits of connectivity to GCP, all within a six-month window. Now that our production environment is migrated and our data centers decommissioned, we are cleaning up the rest of the mess, which includes corporate IT systems. Everything will migrate to managed services wherever possible, operated by contracted L1 and L2 technicians. Everything lives as Terraform code in github; in fact, nobody even has the permissions to instantiate resources manually.
So at the risk of causing the maintainers to dig their heels in more, I would ask you to reconsider your position on this topic, and either vet the original poster's contributed patch, or consider adding a "no snmp" flag in a way that you're comfortable maintaining it.
Aaron
On Sat, Mar 2, 2019 at 8:44 PM Colin Stubbs via observium < observium@observium.org> wrote:
For the benefit of anyone on the list who doesn't use JIRA... and also so that others who support (want/need) this feature can comment.
https://jira.observium.org/browse/OBS-2925
Attached patch defines OBS_SNMP_SKIP flag and uses snmp_skip device attribute, similar to OBS_PING_SKIP and ping_skip, in order to have hosts that are ping only.
Ping only hosts can still have the Observium Unix Agent installed (tested), and other poller modules such as IPMI enabled (untested).
Tested:
- Add/remove/rename ping only hosts via CLI
- Add/remove ping only hosts via webUI
- View/interact ping only hosts via webUI - SNMP specific
features/menus etc are hidden while skip SNMP is enabled 4. Alerting - device_status equals 0 && device_status_type equals ping - will trigger alerts for host down/recovery events 5. Shifting a previously SNMP contactable host to ping only by ticking skip SNMP box - old SNMP graphs/etc are maintained and remain available - remove skip SNMP box and SNMP polling begins again
Things I know kind of don't work right now:
- Location override - poller/discovery doesn't seem to perform
geocoding and whatever else is happening there
Things that could be improved:
- Unix Agent poller module etc is enabled by default for all hosts,
for ping only hosts, perhaps it should be disabled by default? Will improve performance by reducing the number of processes that hang while the 10s default connect timeout happens.
Totally untested:
- Use of autodiscovery SNMP skip - should work in theory, unsure if
those parts of the patch should actually be used though. Some people out there may actually want to add anything that does respond to ping and can be found thru adjacency and routing protocol info etc??
Patch generated from recent trunk, touches files as below,
[root@desktop observium]# diff -r -u observium-trunk root | grep -v ^Only > ping_only_hosts.diff [root@desktop observium]# cd root [root@desktop root]# svn status M add_device.php M html/pages/addhost.inc.php M html/pages/device/edit/device.inc.php M html/pages/device/edit.inc.php M html/pages/device/graphs.inc.php M html/pages/device/perf.inc.php M includes/config-variables.inc.php M includes/defaults.inc.php M includes/definitions.inc.php M includes/discovery/functions.inc.php M includes/functions.inc.php M includes/polling/functions.inc.php M poller.php M rename_device.php [root@desktop root]# svn info | grep ^Revision Revision: 9704 [root@desktop root]# [root@desktop observium]# mv ping_only_hosts.diff ping_only_hosts_r9704.diff
-Colin
Email: cstubbs @ gmail . com _______________________________________________ observium mailing list observium@observium.org http://postman.memetic.org/cgi-bin/mailman/listinfo/observium
--
*Aaron Finney*Infrastructure Engineering | OpenX 888 East Walnut Street, 2nd Floor | Pasadena, CA 91101 o: +1 (626) 466-1141 x6035 | aaron.finney@openx.com
{kind=link}
{kind=link}
{kind=link}