Graphs keep reset randomly and losing previous history

Hi Adam and Observium team:
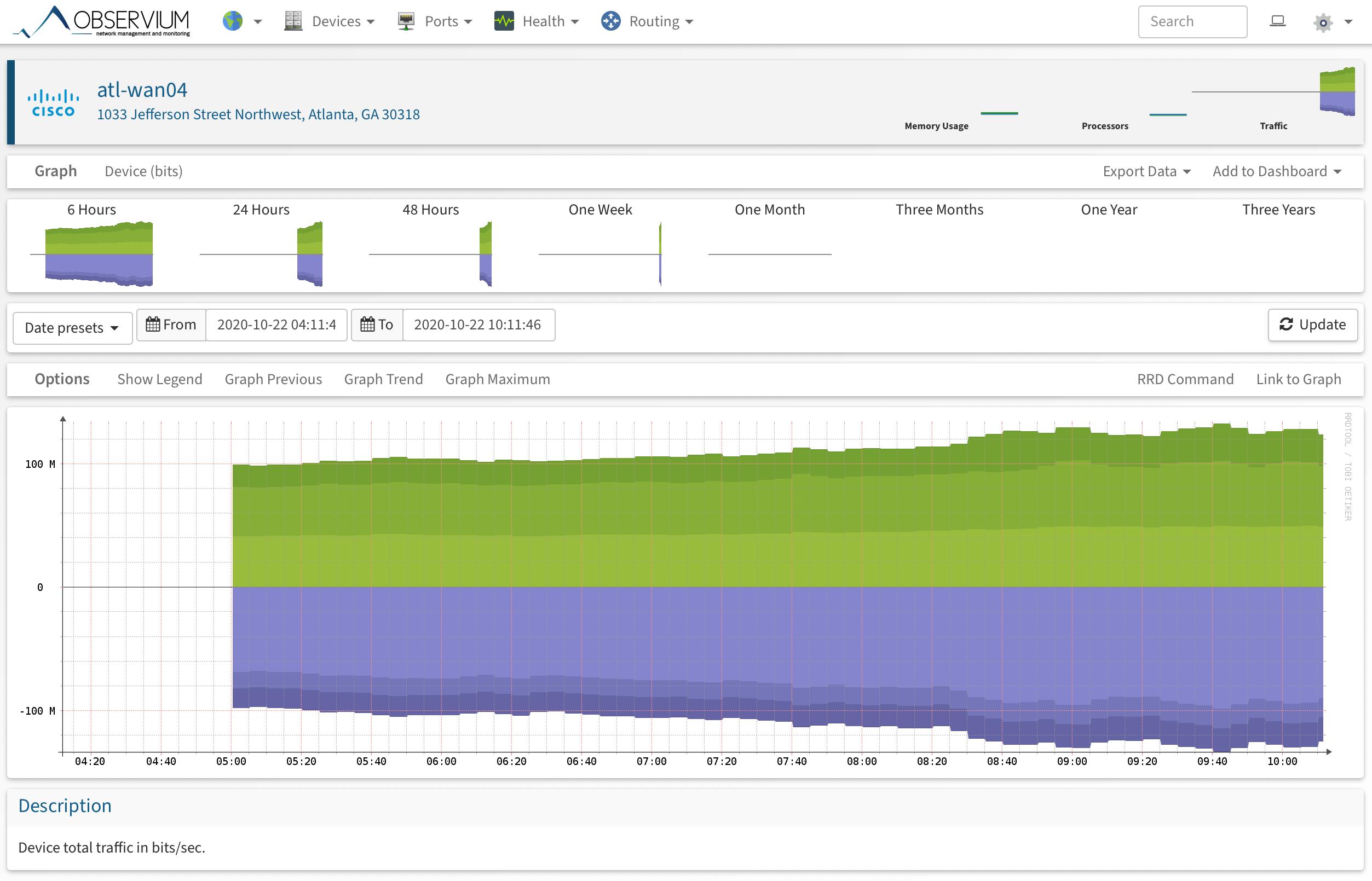
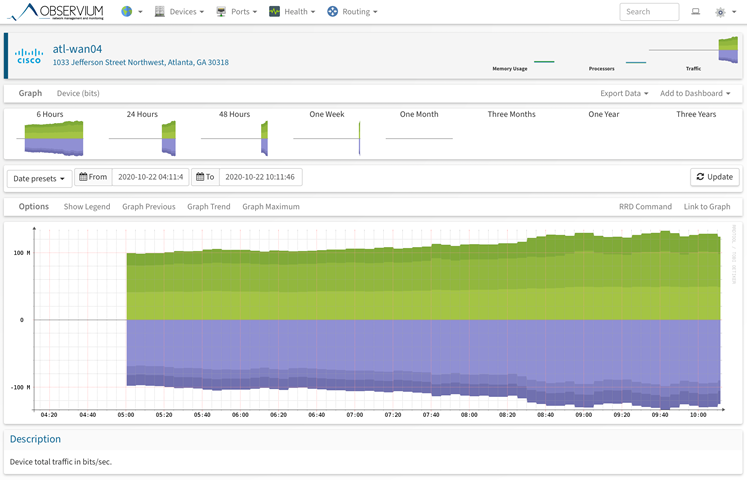
We recently started having an issue with our Observium (20.9.10749) that the graphs for different devices would restart and all its previous history would be gone:
[Graphical user interface Description automatically generated]
And we usually see the following ‘messages’ under /var/log around that time:
Oct 18 05:07:13 sjc-observium-1 rrdcached[1495]: queue_thread_main: rrd_update_r (/opt/observium/rrd/atl-wan04/status.rrd) failed with status -1. (/opt/observium/rrd/atl-wan04/status.rrd: illegal attempt to update using time 1603020715 when last update time is 1603021928 (minimum one second step)) Oct 19 05:12:05 sjc-observium-1 rrdcached[14841]: queue_thread_main: rrd_update_r (/opt/observium/rrd/atl-wan04/status.rrd) failed with status -1. (/opt/observium/rrd/atl-wan04/status.rrd: illegal attempt to update using time 1603106221 when last update time is 1603108322 (minimum one second step)) Oct 20 05:32:47 sjc-observium-1 rrdcached[14471]: queue_thread_main: rrd_update_r (/opt/observium/rrd/atl-wan04/status.rrd) failed with status -1. (/opt/observium/rrd/atl-wan04/status.rrd: illegal attempt to update using time 1603194156 when last update time is 1603194737 (minimum one second step))
We have tried restarting the rrdcached process, and deleting the rrdcached files which are not updated for some time (with the command “find * -type f -mtime +5 -delete” under the rrd directory). But they don’t help much.
Do you have any suggestions how we can further investigate and troubleshoot this?
Thanks.
- Gordon
{kind=link}

The rrd files contain the historical data. If you delete them, the historical data will go away.
This is the only thing that would make the historical data go away, the rrds being removed and then automatically recreated.
As for that log entry, it seems like your system’s clock is going backwards sometimes :
1603020715 when last update time is 1603021928
You were attempting to insert data with the timestamp:
Sunday, 18 October 2020, 11:31:55 AM GMT
But the previous data inserted was at time:
Sunday, 18 October 2020, 11:52:08 AM GMT
There’s some super weird stuff going on with that system.
Adam.
From: Gordon Cheng (gocheng) gocheng@cisco.com Sent: 22 October 2020 18:33 To: Observium observium@observium.org; Adam Armstrong adama@observium.org Subject: Graphs keep reset randomly and losing previous history
Hi Adam and Observium team:
We recently started having an issue with our Observium (20.9.10749) that the graphs for different devices would restart and all its previous history would be gone:
And we usually see the following ‘messages’ under /var/log around that time:
Oct 18 05:07:13 sjc-observium-1 rrdcached[1495]: queue_thread_main: rrd_update_r (/opt/observium/rrd/atl-wan04/status.rrd) failed with status -1. (/opt/observium/rrd/atl-wan04/status.rrd: illegal attempt to update using time 1603020715 when last update time is 1603021928 (minimum one second step))
Oct 19 05:12:05 sjc-observium-1 rrdcached[14841]: queue_thread_main: rrd_update_r (/opt/observium/rrd/atl-wan04/status.rrd) failed with status -1. (/opt/observium/rrd/atl-wan04/status.rrd: illegal attempt to update using time 1603106221 when last update time is 1603108322 (minimum one second step))
Oct 20 05:32:47 sjc-observium-1 rrdcached[14471]: queue_thread_main: rrd_update_r (/opt/observium/rrd/atl-wan04/status.rrd) failed with status -1. (/opt/observium/rrd/atl-wan04/status.rrd: illegal attempt to update using time 1603194156 when last update time is 1603194737 (minimum one second step))
We have tried restarting the rrdcached process, and deleting the rrdcached files which are not updated for some time (with the command “find * -type f -mtime +5 -delete” under the rrd directory). But they don’t help much.
Do you have any suggestions how we can further investigate and troubleshoot this?
Thanks.
- Gordon
{kind=link}

Is it a VM? Clocks on VM can be weird because a loaded hypervisor does not always provide regular time slots. I've seen it cause all sorts of errors in the ntp logs.
In the case of VMWare, they offer a feature "take time from server" (or some such spelling) where the clock is controlled by an installed copy of VMWare Tools on the VM. VMWare tools gets it from the ESXi parent. This actually works quite well and you're recommended to only run ntp on ESXi and not on the VM.
Sadly, I've seen no such option in other hypervisors; but I've only worked with 2 or 3 others.
On 10/22/20 2:47 PM, Adam Armstrong via observium wrote:
The rrd files contain the historical data. If you delete them, the historical data will go away.
This is the only thing that would make the historical data go away, the rrds being removed and then automatically recreated.
As for that log entry, it seems like your system’s clock is going backwards sometimes :
1603020715 when last update time is 1603021928
You were attempting to insert data with the timestamp:
Sunday, 18 October 2020, 11:31:55 AM GMT
But the previous data inserted was at time:
Sunday, 18 October 2020, 11:52:08 AM GMT
There’s some super weird stuff going on with that system.
Adam.
*From:*Gordon Cheng (gocheng) gocheng@cisco.com *Sent:* 22 October 2020 18:33 *To:* Observium observium@observium.org; Adam Armstrong adama@observium.org *Subject:* Graphs keep reset randomly and losing previous history
Hi Adam and Observium team:
We recently started having an issue with our Observium (20.9.10749) that the graphs for different devices would restart and all its previous history would be gone:
Graphical user interface Description automatically generated
And we usually see the following ‘messages’ under /var/log around that time:
Oct 18 05:07:13 sjc-observium-1 rrdcached[1495]: queue_thread_main: rrd_update_r (/opt/observium/rrd/atl-wan04/status.rrd) failed with status -1. (/opt/observium/rrd/atl-wan04/status.rrd: illegal attempt to update using time 1603020715 when last update time is 1603021928 (minimum one second step))
Oct 19 05:12:05 sjc-observium-1 rrdcached[14841]: queue_thread_main: rrd_update_r (/opt/observium/rrd/atl-wan04/status.rrd) failed with status -1. (/opt/observium/rrd/atl-wan04/status.rrd: illegal attempt to update using time 1603106221 when last update time is 1603108322 (minimum one second step))
Oct 20 05:32:47 sjc-observium-1 rrdcached[14471]: queue_thread_main: rrd_update_r (/opt/observium/rrd/atl-wan04/status.rrd) failed with status -1. (/opt/observium/rrd/atl-wan04/status.rrd: illegal attempt to update using time 1603194156 when last update time is 1603194737 (minimum one second step))
We have tried restarting the rrdcached process, and deleting the rrdcached files which are not updated for some time (with the command “find * -type f -mtime +5 -delete” under the rrd directory). But they don’t help much.
Do you have any suggestions how we can further investigate and troubleshoot this?
Thanks.
- Gordon
observium mailing list observium@observium.org https://nam02.safelinks.protection.outlook.com/?url=http%3A%2F%2Fpostman.mem...

Under that scenario (obtaining time from the hypervisor), be careful that ALL of your ESXi hosts have accurate time. Also make sure they have at least 3 time sources defined and reachable (I think the recommendation these days may even be for 5, but 3 should be the minimum for any NTP client).
If a VM is vmotioned acros to another hypervisor, it will do a hard timesync as part of the process, which can cause the time to jump in a single, very large hop (as opposed to the skew limits that NTP would provide to drift the clock over a longer period of time). It is possible that is what's causing your clock to move around a lot.
The VMs will also take reference time from the hypervisor on boot, meaning NTP might have a bit of work to do to adjust the clock to normalise the large offset.
I recall hearing about lower tiers of AWS that are recommended to not run any production workloads on as the client can be periodically frozen or starved of resources such as CPU cycles. I wouldn't expect that to be for 20 minutes at a time though.
This might not be Gordon's exact problem, but hopefully this info might be useful for some others.
Cheers,
M
On 23 Oct 2020, at 6:01 am, Eric W. Bates via observium observium@observium.org wrote:
Is it a VM? Clocks on VM can be weird because a loaded hypervisor does not always provide regular time slots. I've seen it cause all sorts of errors in the ntp logs.
In the case of VMWare, they offer a feature "take time from server" (or some such spelling) where the clock is controlled by an installed copy of VMWare Tools on the VM. VMWare tools gets it from the ESXi parent. This actually works quite well and you're recommended to only run ntp on ESXi and not on the VM.
Sadly, I've seen no such option in other hypervisors; but I've only worked with 2 or 3 others.
On 10/22/20 2:47 PM, Adam Armstrong via observium wrote:
The rrd files contain the historical data. If you delete them, the historical data will go away. This is the only thing that would make the historical data go away, the rrds being removed and then automatically recreated. As for that log entry, it seems like your system’s clock is going backwards sometimes : 1603020715 when last update time is 1603021928 You were attempting to insert data with the timestamp: Sunday, 18 October 2020, 11:31:55 AM GMT But the previous data inserted was at time: Sunday, 18 October 2020, 11:52:08 AM GMT There’s some super weird stuff going on with that system. Adam. *From:*Gordon Cheng (gocheng) gocheng@cisco.com *Sent:* 22 October 2020 18:33 *To:* Observium observium@observium.org; Adam Armstrong adama@observium.org *Subject:* Graphs keep reset randomly and losing previous history Hi Adam and Observium team: We recently started having an issue with our Observium (20.9.10749) that the graphs for different devices would restart and all its previous history would be gone: Graphical user interface Description automatically generated And we usually see the following ‘messages’ under /var/log around that time: Oct 18 05:07:13 sjc-observium-1 rrdcached[1495]: queue_thread_main: rrd_update_r (/opt/observium/rrd/atl-wan04/status.rrd) failed with status -1. (/opt/observium/rrd/atl-wan04/status.rrd: illegal attempt to update using time 1603020715 when last update time is 1603021928 (minimum one second step)) Oct 19 05:12:05 sjc-observium-1 rrdcached[14841]: queue_thread_main: rrd_update_r (/opt/observium/rrd/atl-wan04/status.rrd) failed with status -1. (/opt/observium/rrd/atl-wan04/status.rrd: illegal attempt to update using time 1603106221 when last update time is 1603108322 (minimum one second step)) Oct 20 05:32:47 sjc-observium-1 rrdcached[14471]: queue_thread_main: rrd_update_r (/opt/observium/rrd/atl-wan04/status.rrd) failed with status -1. (/opt/observium/rrd/atl-wan04/status.rrd: illegal attempt to update using time 1603194156 when last update time is 1603194737 (minimum one second step)) We have tried restarting the rrdcached process, and deleting the rrdcached files which are not updated for some time (with the command “find * -type f -mtime +5 -delete” under the rrd directory). But they don’t help much. Do you have any suggestions how we can further investigate and troubleshoot this? Thanks.
- Gordon
observium mailing list observium@observium.org mailto:observium@observium.org https://nam02.safelinks.protection.outlook.com/?url=http%3A%2F%2Fpostman.mem... https://nam02.safelinks.protection.outlook.com/?url=http%3A%2F%2Fpostman.memetic.org%2Fcgi-bin%2Fmailman%2Flistinfo%2Fobservium&data=04%7C01%7Cebates%40whoi.edu%7C43507d02d8c3415b094a08d876baf5b2%7Cd44c5cc6d18c46cc8abd4fdf5b6e5944%7C0%7C0%7C637389892656200801%7CUnknown%7CTWFpbGZsb3d8eyJWIjoiMC4wLjAwMDAiLCJQIjoiV2luMzIiLCJBTiI6Ik1haWwiLCJXVCI6Mn0%3D%7C1000&sdata=S4zCi0RantQvRNaEvLpIvcebYh26gsVAaum5uQ9R7Gg%3D&reserved=0
observium mailing list observium@observium.org mailto:observium@observium.org http://postman.memetic.org/cgi-bin/mailman/listinfo/observium http://postman.memetic.org/cgi-bin/mailman/listinfo/observium
Can this possibly explain a clock going backwards by 20 minutes?
oO
Adam.
Sent from BlueMail
On 22 Oct 2020, 20:01, at 20:01, "Eric W. Bates via observium" observium@observium.org wrote:
Is it a VM? Clocks on VM can be weird because a loaded hypervisor does not always provide regular time slots. I've seen it cause all sorts of errors in the ntp logs.
In the case of VMWare, they offer a feature "take time from server" (or
some such spelling) where the clock is controlled by an installed copy of VMWare Tools on the VM. VMWare tools gets it from the ESXi parent. This actually works quite well and you're recommended to only run ntp on ESXi and not on the VM.
Sadly, I've seen no such option in other hypervisors; but I've only worked with 2 or 3 others.
On 10/22/20 2:47 PM, Adam Armstrong via observium wrote:
The rrd files contain the historical data. If you delete them, the historical data will go away.
This is the only thing that would make the historical data go away,
the
rrds being removed and then automatically recreated.
As for that log entry, it seems like your system’s clock is going backwards sometimes :
1603020715 when last update time is 1603021928
You were attempting to insert data with the timestamp:
Sunday, 18 October 2020, 11:31:55 AM GMT
But the previous data inserted was at time:
Sunday, 18 October 2020, 11:52:08 AM GMT
There’s some super weird stuff going on with that system.
Adam.
*From:*Gordon Cheng (gocheng) gocheng@cisco.com *Sent:* 22 October 2020 18:33 *To:* Observium observium@observium.org; Adam Armstrong adama@observium.org *Subject:* Graphs keep reset randomly and losing previous history
Hi Adam and Observium team:
We recently started having an issue with our Observium (20.9.10749)
that
the graphs for different devices would restart and all its previous history would be gone:
Graphical user interface Description automatically generated
And we usually see the following ‘messages’ under /var/log around
that time:
Oct 18 05:07:13 sjc-observium-1 rrdcached[1495]: queue_thread_main: rrd_update_r (/opt/observium/rrd/atl-wan04/status.rrd) failed with status -1. (/opt/observium/rrd/atl-wan04/status.rrd: illegal attempt
to
update using time 1603020715 when last update time is 1603021928 (minimum one second step))
Oct 19 05:12:05 sjc-observium-1 rrdcached[14841]: queue_thread_main: rrd_update_r (/opt/observium/rrd/atl-wan04/status.rrd) failed with status -1. (/opt/observium/rrd/atl-wan04/status.rrd: illegal attempt
to
update using time 1603106221 when last update time is 1603108322 (minimum one second step))
Oct 20 05:32:47 sjc-observium-1 rrdcached[14471]: queue_thread_main: rrd_update_r (/opt/observium/rrd/atl-wan04/status.rrd) failed with status -1. (/opt/observium/rrd/atl-wan04/status.rrd: illegal attempt
to
update using time 1603194156 when last update time is 1603194737 (minimum one second step))
We have tried restarting the rrdcached process, and deleting the rrdcached files which are not updated for some time (with the command
“find * -type f -mtime +5 -delete” under the rrd directory). But
they
don’t help much.
Do you have any suggestions how we can further investigate and troubleshoot this?
Thanks.
- Gordon
observium mailing list observium@observium.org
https://nam02.safelinks.protection.outlook.com/?url=http%3A%2F%2Fpostman.mem...
observium mailing list observium@observium.org http://postman.memetic.org/cgi-bin/mailman/listinfo/observium
Yes, it can. If the hypervisor clock is that far out of sync.
During boot and also during the vmotion process, the guest does the equivalent of an 'ntpdate' which forcefully syncs the time, regardless of how far offset it is against the local clock (local being the pseudo-clock within the vm).
The concept, at least with vmotion, is to provide a correction for the "stunning" that the VM receives during the process (think of it as being punched in the face). The guest gets momentarily stunned to halt so that memory and CPU state can be copied out from underneath it. It does this repeatedly until all of the state can be transitioned. Obviously, depending on how large/busy the VM is, this could cause the original VM to drift a bit from reality.
M
On 23 Oct 2020, at 7:02 am, Adam Armstrong via observium observium@observium.org wrote:
Can this possibly explain a clock going backwards by 20 minutes?
oO
Adam.
Sent from BlueMail http://www.bluemail.me/r?b=16117 On 22 Oct 2020, at 20:01, "Eric W. Bates via observium" <observium@observium.org mailto:observium@observium.org> wrote: Is it a VM? Clocks on VM can be weird because a loaded hypervisor does not always provide regular time slots. I've seen it cause all sorts of errors in the ntp logs.
In the case of VMWare, they offer a feature "take time from server" (or some such spelling) where the clock is controlled by an installed copy of VMWare Tools on the VM. VMWare tools gets it from the ESXi parent. This actually works quite well and you're recommended to only run ntp on ESXi and not on the VM.
Sadly, I've seen no such option in other hypervisors; but I've only worked with 2 or 3 others.
On 10/22/20 2:47 PM, Adam Armstrong via observium wrote: The rrd files contain the historical data. If you delete them, the historical data will go away.
This is the only thing that would make the historical data go away, the rrds being removed and then automatically recreated.
As for that log entry, it seems like your system’s clock is going backwards sometimes :
1603020715 when last update time is 1603021928
You were attempting to insert data with the timestamp:
Sunday, 18 October 2020, 11:31:55 AM GMT
But the previous data inserted was at time:
Sunday, 18 October 2020, 11:52:08 AM GMT
There’s some super weird stuff going on with that system.
Adam.
*From:*Gordon Cheng (gocheng) gocheng@cisco.com *Sent:* 22 October 2020 18:33 *To:* Observium observium@observium.org; Adam Armstrong adama@observium.org *Subject:* Graphs keep reset randomly and losing previous history
Hi Adam and Observium team:
We recently started having an issue with our Observium (20.9.10749) that the graphs for different devices would restart and all its previous history would be gone:
Graphical user interface Description automatically generated
And we usually see the following ‘messages’ under /var/log around that time:
Oct 18 05:07:13 sjc-observium-1 rrdcached[1495]: queue_thread_main: rrd_update_r (/opt/observium/rrd/atl-wan04/status.rrd) failed with status -1. (/opt/observium/rrd/atl-wan04/status.rrd: illegal attempt to update using time 1603020715 when last update time is 1603021928 (minimum one second step))
Oct 19 05:12:05 sjc-observium-1 rrdcached[14841]: queue_thread_main: rrd_update_r (/opt/observium/rrd/atl-wan04/status.rrd) failed with status -1. (/opt/observium/rrd/atl-wan04/status.rrd: illegal attempt to update using time 1603106221 when last update time is 1603108322 (minimum one second step))
Oct 20 05:32:47 sjc-observium-1 rrdcached[14471]: queue_thread_main: rrd_update_r (/opt/observium/rrd/atl-wan04/status.rrd) failed with status -1. (/opt/observium/rrd/atl-wan04/status.rrd: illegal attempt to update using time 1603194156 when last update time is 1603194737 (minimum one second step))
We have tried restarting the rrdcached process, and deleting the rrdcached files which are not updated for some time (with the command “find * -type f -mtime +5 -delete” under the rrd directory). But they don’t help much.
Do you have any suggestions how we can further investigate and troubleshoot this?
Thanks.
- Gordon
observium mailing list observium@observium.org https://nam02.safelinks.protection.outlook.com/?url=http%3A%2F%2Fpostman.mem... https://nam02.safelinks.protection.outlook.com/?url=http%3A%2F%2Fpostman.memetic.org%2Fcgi-bin%2Fmailman%2Flistinfo%2Fobservium&data=04%7C01%7Cebates%40whoi.edu%7C43507d02d8c3415b094a08d876baf5b2%7Cd44c5cc6d18c46cc8abd4fdf5b6e5944%7C0%7C0%7C637389892656200801%7CUnknown%7CTWFpbGZsb3d8eyJWIjoiMC4wLjAwMDAiLCJQIjoiV2luMzIiLCJBTiI6Ik1haWwiLCJXVCI6Mn0%3D%7C1000&sdata=S4zCi0RantQvRNaEvLpIvcebYh26gsVAaum5uQ9R7Gg%3D&reserved=0
observium mailing list observium@observium.org http://postman.memetic.org/cgi-bin/mailman/listinfo/observium http://postman.memetic.org/cgi-bin/mailman/listinfo/observium _______________________________________________ observium mailing list observium@observium.org http://postman.memetic.org/cgi-bin/mailman/listinfo/observium

That only explains why a VM clock could be 'behind' normal time. Not really how it was a xx *inside the vm* and suddenly it's at xx-30. The sudden timesync could after vmotion, but no sane person would ever sync time from hypervisor to VM.
Tom
On 2020-10-22 22:26, Michael via observium wrote:
Yes, it can. If the hypervisor clock is that far out of sync.
During boot and also during the vmotion process, the guest does the equivalent of an 'ntpdate' which forcefully syncs the time, regardless of how far offset it is against the local clock (local being the pseudo-clock within the vm).
The concept, at least with vmotion, is to provide a correction for the "stunning" that the VM receives during the process (think of it as being punched in the face). The guest gets momentarily stunned to halt so that memory and CPU state can be copied out from underneath it. It does this repeatedly until all of the state can be transitioned. Obviously, depending on how large/busy the VM is, this could cause the original VM to drift a bit from reality.
M
On 23 Oct 2020, at 7:02 am, Adam Armstrong via observium <observium@observium.org mailto:observium@observium.org> wrote:
Can this possibly explain a clock going backwards by 20 minutes?
oO
Adam.
Sent from BlueMail http://www.bluemail.me/r?b=16117
Here's some other references for it.
https://serverfault.com/questions/840874/immediately-fix-system-clock-after-...
https://kb.vmware.com/s/article/2108828
The VMWare article does talk about the vm time falling behind (which is expected during the vmotion process, it would never advance forward), but it doesn't specifically cover the scenario when the vm is now ahead of time (when compared to the destination host).
I would assume that the settings referenced in the articles will really just apply a +/- threshold (default: 1000ms) to the clock and force a sync if required.
On 23 Oct 2020, at 7:26 am, Michael via observium observium@observium.org wrote:
Yes, it can. If the hypervisor clock is that far out of sync.
During boot and also during the vmotion process, the guest does the equivalent of an 'ntpdate' which forcefully syncs the time, regardless of how far offset it is against the local clock (local being the pseudo-clock within the vm).
The concept, at least with vmotion, is to provide a correction for the "stunning" that the VM receives during the process (think of it as being punched in the face). The guest gets momentarily stunned to halt so that memory and CPU state can be copied out from underneath it. It does this repeatedly until all of the state can be transitioned. Obviously, depending on how large/busy the VM is, this could cause the original VM to drift a bit from reality.
M
On 23 Oct 2020, at 7:02 am, Adam Armstrong via observium <observium@observium.org mailto:observium@observium.org> wrote:
Can this possibly explain a clock going backwards by 20 minutes?
oO
Adam.
Sent from BlueMail http://www.bluemail.me/r?b=16117 On 22 Oct 2020, at 20:01, "Eric W. Bates via observium" <observium@observium.org mailto:observium@observium.org> wrote: Is it a VM? Clocks on VM can be weird because a loaded hypervisor does not always provide regular time slots. I've seen it cause all sorts of errors in the ntp logs.
In the case of VMWare, they offer a feature "take time from server" (or some such spelling) where the clock is controlled by an installed copy of VMWare Tools on the VM. VMWare tools gets it from the ESXi parent. This actually works quite well and you're recommended to only run ntp on ESXi and not on the VM.
Sadly, I've seen no such option in other hypervisors; but I've only worked with 2 or 3 others.
On 10/22/20 2:47 PM, Adam Armstrong via observium wrote: The rrd files contain the historical data. If you delete them, the historical data will go away.
This is the only thing that would make the historical data go away, the rrds being removed and then automatically recreated.
As for that log entry, it seems like your system’s clock is going backwards sometimes :
1603020715 when last update time is 1603021928
You were attempting to insert data with the timestamp:
Sunday, 18 October 2020, 11:31:55 AM GMT
But the previous data inserted was at time:
Sunday, 18 October 2020, 11:52:08 AM GMT
There’s some super weird stuff going on with that system.
Adam.
*From:*Gordon Cheng (gocheng) <gocheng@cisco.com mailto:gocheng@cisco.com> *Sent:* 22 October 2020 18:33 *To:* Observium <observium@observium.org mailto:observium@observium.org>; Adam Armstrong <adama@observium.org mailto:adama@observium.org> *Subject:* Graphs keep reset randomly and losing previous history
Hi Adam and Observium team:
We recently started having an issue with our Observium (20.9.10749) that the graphs for different devices would restart and all its previous history would be gone:
Graphical user interface Description automatically generated
And we usually see the following ‘messages’ under /var/log around that time:
Oct 18 05:07:13 sjc-observium-1 rrdcached[1495]: queue_thread_main: rrd_update_r (/opt/observium/rrd/atl-wan04/status.rrd) failed with status -1. (/opt/observium/rrd/atl-wan04/status.rrd: illegal attempt to update using time 1603020715 when last update time is 1603021928 (minimum one second step))
Oct 19 05:12:05 sjc-observium-1 rrdcached[14841]: queue_thread_main: rrd_update_r (/opt/observium/rrd/atl-wan04/status.rrd) failed with status -1. (/opt/observium/rrd/atl-wan04/status.rrd: illegal attempt to update using time 1603106221 when last update time is 1603108322 (minimum one second step))
Oct 20 05:32:47 sjc-observium-1 rrdcached[14471]: queue_thread_main: rrd_update_r (/opt/observium/rrd/atl-wan04/status.rrd) failed with status -1. (/opt/observium/rrd/atl-wan04/status.rrd: illegal attempt to update using time 1603194156 when last update time is 1603194737 (minimum one second step))
We have tried restarting the rrdcached process, and deleting the rrdcached files which are not updated for some time (with the command “find * -type f -mtime +5 -delete” under the rrd directory). But they don’t help much.
Do you have any suggestions how we can further investigate and troubleshoot this?
Thanks.
- Gordon
observium mailing list observium@observium.org mailto:observium@observium.org https://nam02.safelinks.protection.outlook.com/?url=http%3A%2F%2Fpostman.mem... https://nam02.safelinks.protection.outlook.com/?url=http%3A%2F%2Fpostman.memetic.org%2Fcgi-bin%2Fmailman%2Flistinfo%2Fobservium&data=04%7C01%7Cebates%40whoi.edu%7C43507d02d8c3415b094a08d876baf5b2%7Cd44c5cc6d18c46cc8abd4fdf5b6e5944%7C0%7C0%7C637389892656200801%7CUnknown%7CTWFpbGZsb3d8eyJWIjoiMC4wLjAwMDAiLCJQIjoiV2luMzIiLCJBTiI6Ik1haWwiLCJXVCI6Mn0%3D%7C1000&sdata=S4zCi0RantQvRNaEvLpIvcebYh26gsVAaum5uQ9R7Gg%3D&reserved=0
observium mailing list observium@observium.org mailto:observium@observium.org http://postman.memetic.org/cgi-bin/mailman/listinfo/observium http://postman.memetic.org/cgi-bin/mailman/listinfo/observium _______________________________________________ observium mailing list observium@observium.org mailto:observium@observium.org http://postman.memetic.org/cgi-bin/mailman/listinfo/observium
observium mailing list observium@observium.org http://postman.memetic.org/cgi-bin/mailman/listinfo/observium
participants (5)
-
 Adam Armstrong
Adam Armstrong -
 Eric W. Bates
Eric W. Bates -
 Gordon Cheng (gocheng)
Gordon Cheng (gocheng) -
 Michael
Michael -
 Tom Laermans
Tom Laermans