
Hi Guys,
Got a weird issue which has just started, seemingly by itself but I imagine there was a cause (I just don't know it yet!).
In short, every 30 minute the poller decides that approximately a third of all devices (92 in total) are 'Offline'. They then magically recover on the next poller interval.
The devices are not offline, and the Observium host does not loose connectivity (I've tested with numerous pings etc. during this predictable failure period).
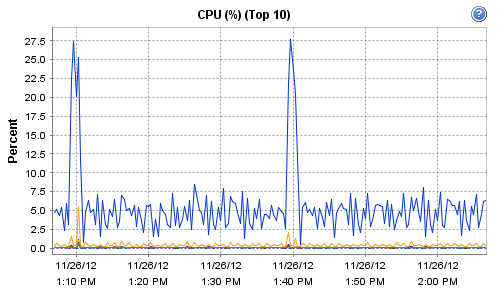
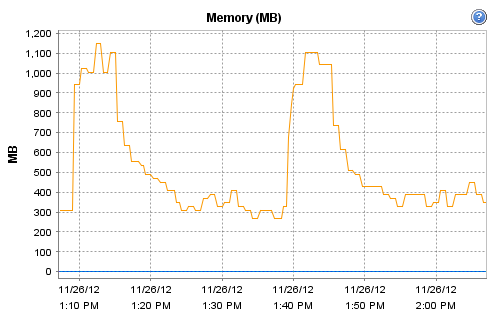
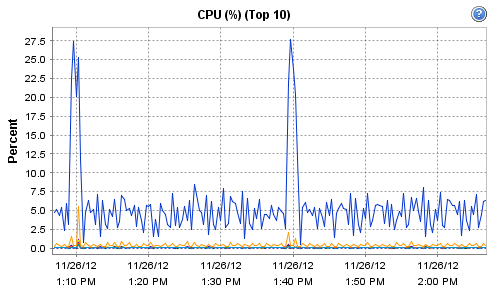
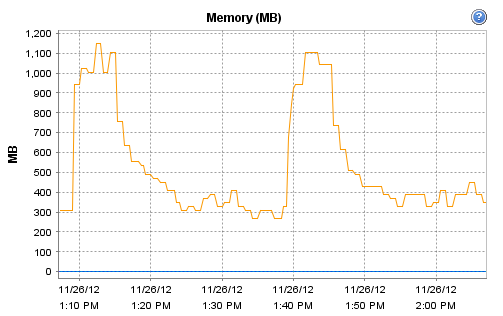
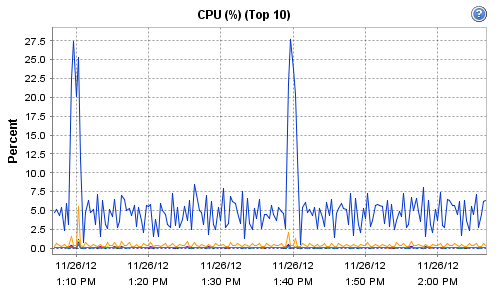
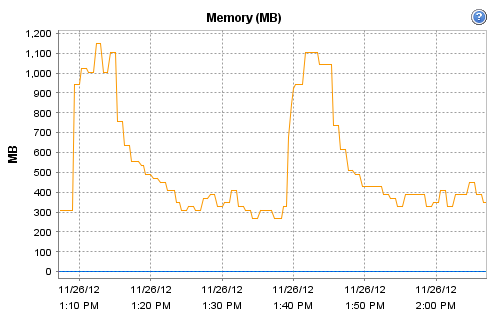
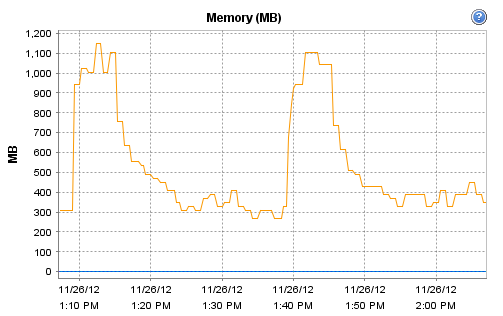
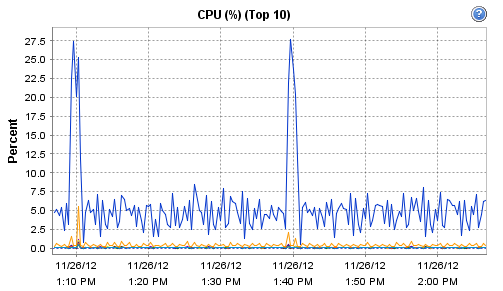
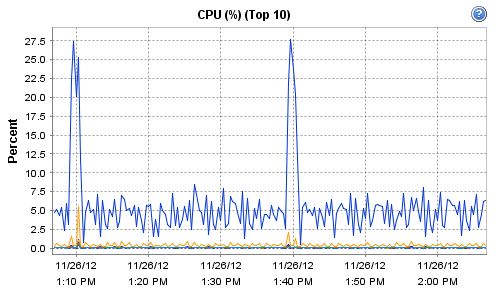
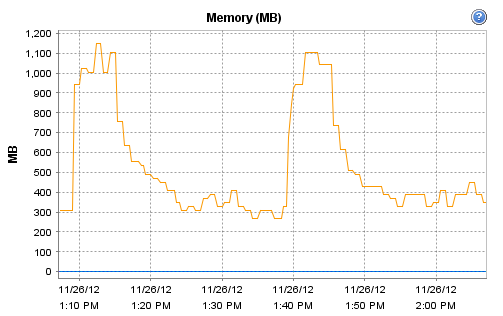
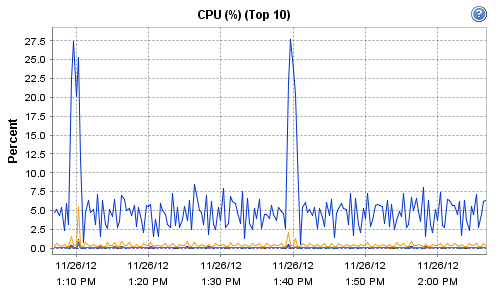
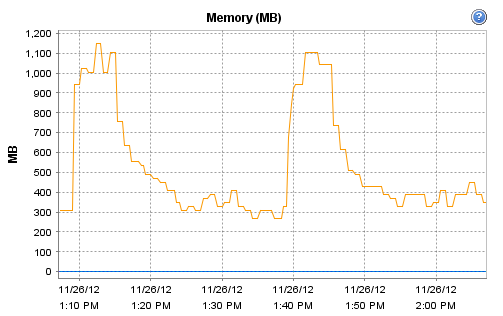
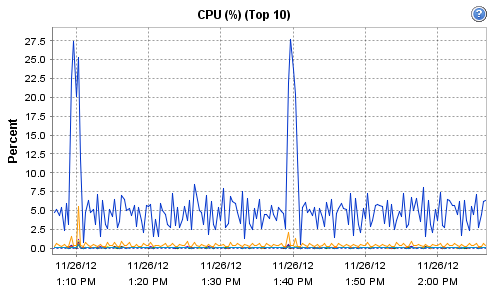
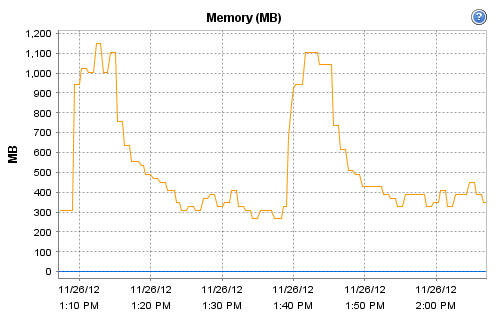
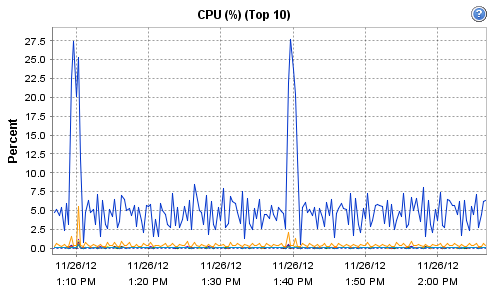
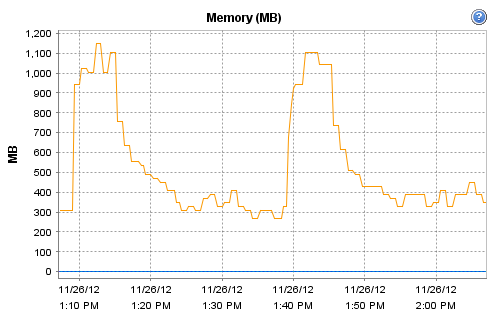
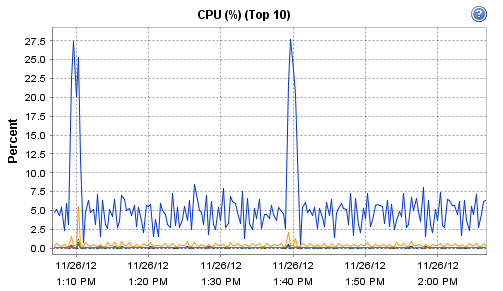
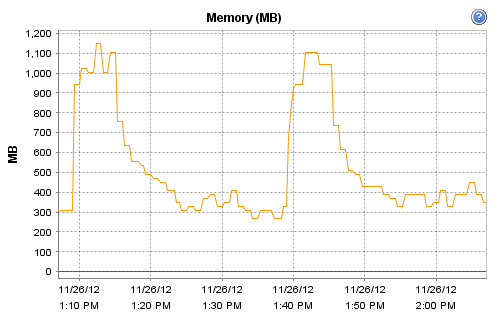
Interestingly, the host on which Observium runs does record these interesting CPU and RAM metrics during that particular polling run:
[cid:image001.png@01CDCBDF.93DC5B50]
[cid:image002.png@01CDCBDF.93DC5B50]
Now, I'm guessing that there is maybe a more substantial 'discovery' run or similar every 30 minutes. For some reason, this more intensive run seems to be resulting in a load of devices going allegedly offline.
The problem started on Friday around 11pm and has repeated like clockwork since. We are running the latest SVN.
I'm a bit uncertain where to start with this one as although it's predictable I can't really see anything which would cause it to happen. Pointers for diagnosing further very welcome :)
Cheers as always!
Robert Williams
Custodian DataCentre
email: Robert@CustodianDC.com
{kind=link}
{kind=link}

Look for other, newly added cron jobs. Discovery is only run once every 6 hours.
It's pretty difficult to make the poller believe that something is offline without network issues, as all it does to decide is a ping and an snmp get.
adam.
On 26/11/2012 08:14, Robert Williams wrote:
Hi Guys,
Got a weird issue which has just started, seemingly by itself but I imagine there was a cause (I just don't know it yet!).
In short, every 30 minute the poller decides that approximately a third of all devices (92 in total) are 'Offline'. They then magically recover on the next poller interval.
The devices are not offline, and the Observium host does not loose connectivity (I've tested with numerous pings etc. during this predictable failure period).
Interestingly, the host on which Observium runs does record these interesting CPU and RAM metrics during that particular polling run:
Now, I'm guessing that there is maybe a more substantial 'discovery' run or similar every 30 minutes. For some reason, this more intensive run seems to be resulting in a load of devices going allegedly offline.
The problem started on Friday around 11pm and has repeated like clockwork since. We are running the latest SVN.
I'm a bit uncertain where to start with this one as although it's predictable I can't really see anything which would cause it to happen. Pointers for diagnosing further very welcome J
Cheers as always!
*Robert Williams*
Custodian DataCentre
email: Robert@CustodianDC.com
observium mailing list observium@observium.org http://postman.memetic.org/cgi-bin/mailman/listinfo/observium
{kind=link}
{kind=link}
Hi - no other cron jobs on that box, it's purely running Observium and the only jobs are the poller itself and a selection of jobs which run at weekly or daily intervals for various system functions. There is also a weekly SVN pull for Observium :)
As a test we have removed the most recently added device to see if that helps, but I could do with some way of recording what is happening on that particular poll. It's like clockwork but I can't see anything that would cause that on the network side, and everything definitely responds (from the Observium console) 100% during the poll itself.
Cheers!
Robert Williams
Custodian DataCentre
email: Robert@CustodianDC.com
From: observium-bounces@observium.org [mailto:observium-bounces@observium.org] On Behalf Of Adam Armstrong Sent: 26 November 2012 16:07 To: Observium Network Observation System Subject: Re: [Observium] 30 minute poll issue
Look for other, newly added cron jobs. Discovery is only run once every 6 hours.
It's pretty difficult to make the poller believe that something is offline without network issues, as all it does to decide is a ping and an snmp get.
adam.
On 26/11/2012 08:14, Robert Williams wrote: Hi Guys,
Got a weird issue which has just started, seemingly by itself but I imagine there was a cause (I just don't know it yet!).
In short, every 30 minute the poller decides that approximately a third of all devices (92 in total) are 'Offline'. They then magically recover on the next poller interval.
The devices are not offline, and the Observium host does not loose connectivity (I've tested with numerous pings etc. during this predictable failure period).
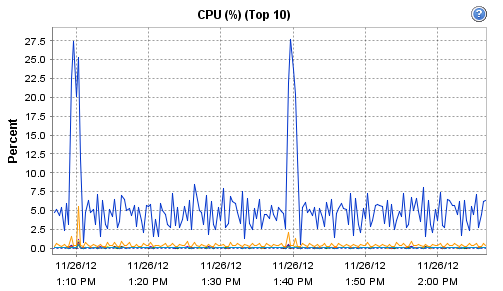
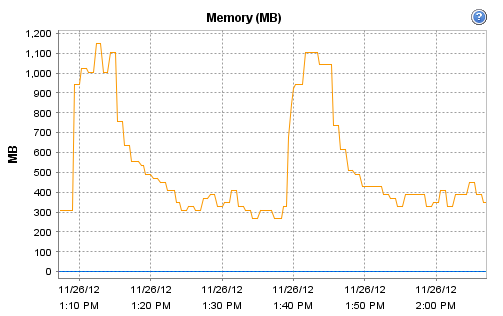
Interestingly, the host on which Observium runs does record these interesting CPU and RAM metrics during that particular polling run:
[cid:image001.png@01CDCBF4.739CFF60]
[cid:image002.png@01CDCBF4.739CFF60]
Now, I'm guessing that there is maybe a more substantial 'discovery' run or similar every 30 minutes. For some reason, this more intensive run seems to be resulting in a load of devices going allegedly offline.
The problem started on Friday around 11pm and has repeated like clockwork since. We are running the latest SVN.
I'm a bit uncertain where to start with this one as although it's predictable I can't really see anything which would cause it to happen. Pointers for diagnosing further very welcome :)
Cheers as always!
Robert Williams
Custodian DataCentre
email: Robert@CustodianDC.commailto:Robert@CustodianDC.com
_______________________________________________
observium mailing list
observium@observium.orgmailto:observium@observium.org
http://postman.memetic.org/cgi-bin/mailman/listinfo/observium
{kind=link}
{kind=link}

I believe something wrong on your box durring this poll someone eat up all CPU thus observium can't get enough during poll. Probably should debug which process eat cpu every 30 mins.
On 26.11.2012 20:38, Robert Williams wrote:
Hi - no other cron jobs on that box, it's purely running Observium and the only jobs are the poller itself and a selection of jobs which run at weekly or daily intervals for various system functions. There is also a weekly SVN pull for Observium :)
As a test we have removed the most recently added device to see if that helps, but I could do with some way of recording what is happening on that particular poll. It's like clockwork but I can't see anything that would cause that on the network side, and everything definitely responds (from the Observium console) 100% during the poll itself.
Cheers!
Robert Williams
Custodian DataCentre
email: Robert@CustodianDC.com
From: observium-bounces@observium.org [mailto:observium-bounces@observium.org] On Behalf Of Adam Armstrong Sent: 26 November 2012 16:07 To: Observium Network Observation System Subject: Re: [Observium] 30 minute poll issue
Look for other, newly added cron jobs. Discovery is only run once every 6 hours.
It's pretty difficult to make the poller believe that something is offline without network issues, as all it does to decide is a ping and an snmp get.
adam.
On 26/11/2012 08:14, Robert Williams wrote: Hi Guys,
Got a weird issue which has just started, seemingly by itself but I imagine there was a cause (I just don't know it yet!).
In short, every 30 minute the poller decides that approximately a third of all devices (92 in total) are 'Offline'. They then magically recover on the next poller interval.
The devices are not offline, and the Observium host does not loose connectivity (I've tested with numerous pings etc. during this predictable failure period).
Interestingly, the host on which Observium runs does record these interesting CPU and RAM metrics during that particular polling run:
[cid:image001.png@01CDCBF4.739CFF60]
[cid:image002.png@01CDCBF4.739CFF60]
Now, I'm guessing that there is maybe a more substantial 'discovery' run or similar every 30 minutes. For some reason, this more intensive run seems to be resulting in a load of devices going allegedly offline.
The problem started on Friday around 11pm and has repeated like clockwork since. We are running the latest SVN.
I'm a bit uncertain where to start with this one as although it's predictable I can't really see anything which would cause it to happen. Pointers for diagnosing further very welcome :)
Cheers as always!
Robert Williams
Custodian DataCentre
email: Robert@CustodianDC.commailto:Robert@CustodianDC.com
observium mailing list
observium@observium.orgmailto:observium@observium.org
http://postman.memetic.org/cgi-bin/mailman/listinfo/observium
observium mailing list observium@observium.org http://postman.memetic.org/cgi-bin/mailman/listinfo/observium
It sounds like a cron job doing something bad, possibly hitting a bit of the disk with corruption.
Anything in dmesg?
adam.
On 26/11/2012 10:38, Robert Williams wrote:
Hi -- no other cron jobs on that box, it's purely running Observium and the only jobs are the poller itself and a selection of jobs which run at weekly or daily intervals for various system functions. There is also a weekly SVN pull for Observium :)
As a test we have removed the most recently added device to see if that helps, but I could do with some way of recording what is happening on that particular poll. It's like clockwork but I can't see anything that would cause that on the network side, and everything definitely responds (from the Observium console) 100% during the poll itself.
Cheers!
*Robert Williams*
Custodian DataCentre
email: Robert@CustodianDC.com
*From:*observium-bounces@observium.org [mailto:observium-bounces@observium.org] *On Behalf Of *Adam Armstrong *Sent:* 26 November 2012 16:07 *To:* Observium Network Observation System *Subject:* Re: [Observium] 30 minute poll issue
Look for other, newly added cron jobs. Discovery is only run once every 6 hours.
It's pretty difficult to make the poller believe that something is offline without network issues, as all it does to decide is a ping and an snmp get.
adam.
On 26/11/2012 08:14, Robert Williams wrote:
Hi Guys, Got a weird issue which has just started, seemingly by itself but I imagine there was a cause (I just don't know it yet!). In short, every 30 minute the poller decides that approximately a third of all devices (92 in total) are 'Offline'. They then magically recover on the next poller interval. The devices are not offline, and the Observium host does not loose connectivity (I've tested with numerous pings etc. during this predictable failure period). Interestingly, the host on which Observium runs does record these interesting CPU and RAM metrics during that particular polling run: Now, I'm guessing that there is maybe a more substantial 'discovery' run or similar every 30 minutes. For some reason, this more intensive run seems to be resulting in a load of devices going allegedly offline. The problem started on Friday around 11pm and has repeated like clockwork since. We are running the latest SVN. I'm a bit uncertain where to start with this one as although it's predictable I can't really see anything which would cause it to happen. Pointers for diagnosing further very welcome J Cheers as always! *Robert Williams* Custodian DataCentre email: Robert@CustodianDC.com <mailto:Robert@CustodianDC.com> _______________________________________________ observium mailing list observium@observium.org <mailto:observium@observium.org> http://postman.memetic.org/cgi-bin/mailman/listinfo/observium
observium mailing list observium@observium.org http://postman.memetic.org/cgi-bin/mailman/listinfo/observium
{kind=link}
{kind=link}
Btw, when one single installation out of thousands starts doing something like this, it's almost never related to the code, and almost always related to the system it's installed on.
adam.
On 26/11/2012 10:38, Robert Williams wrote:
Hi -- no other cron jobs on that box, it's purely running Observium and the only jobs are the poller itself and a selection of jobs which run at weekly or daily intervals for various system functions. There is also a weekly SVN pull for Observium :)
As a test we have removed the most recently added device to see if that helps, but I could do with some way of recording what is happening on that particular poll. It's like clockwork but I can't see anything that would cause that on the network side, and everything definitely responds (from the Observium console) 100% during the poll itself.
Cheers!
*Robert Williams*
Custodian DataCentre
email: Robert@CustodianDC.com
*From:*observium-bounces@observium.org [mailto:observium-bounces@observium.org] *On Behalf Of *Adam Armstrong *Sent:* 26 November 2012 16:07 *To:* Observium Network Observation System *Subject:* Re: [Observium] 30 minute poll issue
Look for other, newly added cron jobs. Discovery is only run once every 6 hours.
It's pretty difficult to make the poller believe that something is offline without network issues, as all it does to decide is a ping and an snmp get.
adam.
On 26/11/2012 08:14, Robert Williams wrote:
Hi Guys, Got a weird issue which has just started, seemingly by itself but I imagine there was a cause (I just don't know it yet!). In short, every 30 minute the poller decides that approximately a third of all devices (92 in total) are 'Offline'. They then magically recover on the next poller interval. The devices are not offline, and the Observium host does not loose connectivity (I've tested with numerous pings etc. during this predictable failure period). Interestingly, the host on which Observium runs does record these interesting CPU and RAM metrics during that particular polling run: Now, I'm guessing that there is maybe a more substantial 'discovery' run or similar every 30 minutes. For some reason, this more intensive run seems to be resulting in a load of devices going allegedly offline. The problem started on Friday around 11pm and has repeated like clockwork since. We are running the latest SVN. I'm a bit uncertain where to start with this one as although it's predictable I can't really see anything which would cause it to happen. Pointers for diagnosing further very welcome J Cheers as always! *Robert Williams* Custodian DataCentre email: Robert@CustodianDC.com <mailto:Robert@CustodianDC.com> _______________________________________________ observium mailing list observium@observium.org <mailto:observium@observium.org> http://postman.memetic.org/cgi-bin/mailman/listinfo/observium
observium mailing list observium@observium.org http://postman.memetic.org/cgi-bin/mailman/listinfo/observium
{kind=link}
{kind=link}
Right - I've disabled a few of the recent additions and each time I disable one the number of hosts which are 'down' decreases. Now, with 3 hosts disabled I only have 2 hosts which are failing.
Also, the hosts which fail are always numbered sequentially and are always high-numbered, say above host ID 90.
Is it possible the poller is simply running out of time? Can the time be extended? Either way, why only on exactly every 6 polls / 30 minutes? Weird...
Robert Williams
Custodian DataCentre
email: Robert@CustodianDC.com
From: observium-bounces@observium.org [mailto:observium-bounces@observium.org] On Behalf Of Adam Armstrong Sent: 26 November 2012 16:58 To: Observium Network Observation System Subject: Re: [Observium] 30 minute poll issue
Btw, when one single installation out of thousands starts doing something like this, it's almost never related to the code, and almost always related to the system it's installed on.
adam.
On 26/11/2012 10:38, Robert Williams wrote: Hi - no other cron jobs on that box, it's purely running Observium and the only jobs are the poller itself and a selection of jobs which run at weekly or daily intervals for various system functions. There is also a weekly SVN pull for Observium :)
As a test we have removed the most recently added device to see if that helps, but I could do with some way of recording what is happening on that particular poll. It's like clockwork but I can't see anything that would cause that on the network side, and everything definitely responds (from the Observium console) 100% during the poll itself.
Cheers!
Robert Williams
Custodian DataCentre
email: Robert@CustodianDC.commailto:Robert@CustodianDC.com
From: observium-bounces@observium.orgmailto:observium-bounces@observium.org [mailto:observium-bounces@observium.org] On Behalf Of Adam Armstrong Sent: 26 November 2012 16:07 To: Observium Network Observation System Subject: Re: [Observium] 30 minute poll issue
Look for other, newly added cron jobs. Discovery is only run once every 6 hours.
It's pretty difficult to make the poller believe that something is offline without network issues, as all it does to decide is a ping and an snmp get.
adam.
On 26/11/2012 08:14, Robert Williams wrote: Hi Guys,
Got a weird issue which has just started, seemingly by itself but I imagine there was a cause (I just don't know it yet!).
In short, every 30 minute the poller decides that approximately a third of all devices (92 in total) are 'Offline'. They then magically recover on the next poller interval.
The devices are not offline, and the Observium host does not loose connectivity (I've tested with numerous pings etc. during this predictable failure period).
Interestingly, the host on which Observium runs does record these interesting CPU and RAM metrics during that particular polling run:
[cid:image001.png@01CDCC03.42D70B50]
[cid:image002.png@01CDCC03.42D70B50]
Now, I'm guessing that there is maybe a more substantial 'discovery' run or similar every 30 minutes. For some reason, this more intensive run seems to be resulting in a load of devices going allegedly offline.
The problem started on Friday around 11pm and has repeated like clockwork since. We are running the latest SVN.
I'm a bit uncertain where to start with this one as although it's predictable I can't really see anything which would cause it to happen. Pointers for diagnosing further very welcome :)
Cheers as always!
Robert Williams
Custodian DataCentre
email: Robert@CustodianDC.commailto:Robert@CustodianDC.com
_______________________________________________
observium mailing list
observium@observium.orgmailto:observium@observium.org
http://postman.memetic.org/cgi-bin/mailman/listinfo/observium
_______________________________________________
observium mailing list
observium@observium.orgmailto:observium@observium.org
http://postman.memetic.org/cgi-bin/mailman/listinfo/observium
{kind=link}
{kind=link}
You're looking in completely the wrong place, and you've totally ignored everything i've said, so I give up.
have fun.
On 26/11/2012 12:24, Robert Williams wrote:
Right -- I've disabled a few of the recent additions and each time I disable one the number of hosts which are 'down' decreases. Now, with 3 hosts disabled I only have 2 hosts which are failing.
Also, the hosts which fail are always numbered sequentially and are always high-numbered, say above host ID 90.
Is it possible the poller is simply running out of time? Can the time be extended? Either way, why only on exactly every 6 polls / 30 minutes? Weird...
*Robert Williams*
Custodian DataCentre
email: Robert@CustodianDC.com
*From:*observium-bounces@observium.org [mailto:observium-bounces@observium.org] *On Behalf Of *Adam Armstrong *Sent:* 26 November 2012 16:58 *To:* Observium Network Observation System *Subject:* Re: [Observium] 30 minute poll issue
Btw, when one single installation out of thousands starts doing something like this, it's almost never related to the code, and almost always related to the system it's installed on.
adam.
On 26/11/2012 10:38, Robert Williams wrote:
Hi -- no other cron jobs on that box, it's purely running Observium and the only jobs are the poller itself and a selection of jobs which run at weekly or daily intervals for various system functions. There is also a weekly SVN pull for Observium :) As a test we have removed the most recently added device to see if that helps, but I could do with some way of recording what is happening on that particular poll. It's like clockwork but I can't see anything that would cause that on the network side, and everything definitely responds (from the Observium console) 100% during the poll itself. Cheers! *Robert Williams* Custodian DataCentre email: Robert@CustodianDC.com <mailto:Robert@CustodianDC.com> *From:*observium-bounces@observium.org <mailto:observium-bounces@observium.org> [mailto:observium-bounces@observium.org] *On Behalf Of *Adam Armstrong *Sent:* 26 November 2012 16:07 *To:* Observium Network Observation System *Subject:* Re: [Observium] 30 minute poll issue Look for other, newly added cron jobs. Discovery is only run once every 6 hours. It's pretty difficult to make the poller believe that something is offline without network issues, as all it does to decide is a ping and an snmp get. adam. On 26/11/2012 08:14, Robert Williams wrote: Hi Guys, Got a weird issue which has just started, seemingly by itself but I imagine there was a cause (I just don't know it yet!). In short, every 30 minute the poller decides that approximately a third of all devices (92 in total) are 'Offline'. They then magically recover on the next poller interval. The devices are not offline, and the Observium host does not loose connectivity (I've tested with numerous pings etc. during this predictable failure period). Interestingly, the host on which Observium runs does record these interesting CPU and RAM metrics during that particular polling run: Now, I'm guessing that there is maybe a more substantial 'discovery' run or similar every 30 minutes. For some reason, this more intensive run seems to be resulting in a load of devices going allegedly offline. The problem started on Friday around 11pm and has repeated like clockwork since. We are running the latest SVN. I'm a bit uncertain where to start with this one as although it's predictable I can't really see anything which would cause it to happen. Pointers for diagnosing further very welcome J Cheers as always! *Robert Williams* Custodian DataCentre email: Robert@CustodianDC.com <mailto:Robert@CustodianDC.com> _______________________________________________ observium mailing list observium@observium.org <mailto:observium@observium.org> http://postman.memetic.org/cgi-bin/mailman/listinfo/observium _______________________________________________ observium mailing list observium@observium.org <mailto:observium@observium.org> http://postman.memetic.org/cgi-bin/mailman/listinfo/observium
observium mailing list observium@observium.org http://postman.memetic.org/cgi-bin/mailman/listinfo/observium
{kind=link}
{kind=link}
Hi, well any ignoring you think I'm doing is certainly not the case - you said to check for other cron jobs and I did. There aren't any (literally, this system has only Observium on it). I also checked for any processes running at the point of the 'host down' events as was also suggested; the only one is the poller / php process itself. Which takes more CPU on every 6th poll, but nothing more interesting than that. If there were other suggestions then I'm really sorry I've obviously missed them (which is quite likely as I've noticed before some postings from this list have been dropped by our filtering system). Either way, I'm certainly not ignoring you, I think it would be a bit stupid to ignore any advice from the creator of the product which you are having trouble with :)
Always suspect the last change you made broke it - so since there were five or six hosts added last week my initial suspicion was maybe the poller was running out of time. The higher number hosts failing, in order, suggested to me that (assuming it polls them in numerical order) again maybe it is running out of time before completing. This was slightly confirmed by removing hosts at random and suddenly the problem went away.
I'm just trying to fault-find at the same time as asking for pointers and I'm happy to check anything that anyone on here may suggest.
Incidentally I'm just deploying Job's poller-wrapper script which I've been meaning to do for a while but never got around to it. I'll know in 30 minutes or so if it's helped at all and I'll let you know.
In the meantime, please do let me know if I've missed or ignored something, as I've most certainly not intended to - cheers!
Robert Williams
Custodian DataCentre
email: Robert@CustodianDC.com
From: observium-bounces@observium.org [mailto:observium-bounces@observium.org] On Behalf Of Adam Armstrong Sent: 26 November 2012 18:59 To: Observium Network Observation System Subject: Re: [Observium] 30 minute poll issue
You're looking in completely the wrong place, and you've totally ignored everything i've said, so I give up.
have fun.
On 26/11/2012 12:24, Robert Williams wrote: Right - I've disabled a few of the recent additions and each time I disable one the number of hosts which are 'down' decreases. Now, with 3 hosts disabled I only have 2 hosts which are failing.
Also, the hosts which fail are always numbered sequentially and are always high-numbered, say above host ID 90.
Is it possible the poller is simply running out of time? Can the time be extended? Either way, why only on exactly every 6 polls / 30 minutes? Weird...
Robert Williams
Custodian DataCentre
email: Robert@CustodianDC.commailto:Robert@CustodianDC.com
From: observium-bounces@observium.orgmailto:observium-bounces@observium.org [mailto:observium-bounces@observium.org] On Behalf Of Adam Armstrong Sent: 26 November 2012 16:58 To: Observium Network Observation System Subject: Re: [Observium] 30 minute poll issue
Btw, when one single installation out of thousands starts doing something like this, it's almost never related to the code, and almost always related to the system it's installed on.
adam.
On 26/11/2012 10:38, Robert Williams wrote: Hi - no other cron jobs on that box, it's purely running Observium and the only jobs are the poller itself and a selection of jobs which run at weekly or daily intervals for various system functions. There is also a weekly SVN pull for Observium :)
As a test we have removed the most recently added device to see if that helps, but I could do with some way of recording what is happening on that particular poll. It's like clockwork but I can't see anything that would cause that on the network side, and everything definitely responds (from the Observium console) 100% during the poll itself.
Cheers!
Robert Williams
Custodian DataCentre
email: Robert@CustodianDC.commailto:Robert@CustodianDC.com
From: observium-bounces@observium.orgmailto:observium-bounces@observium.org [mailto:observium-bounces@observium.org] On Behalf Of Adam Armstrong Sent: 26 November 2012 16:07 To: Observium Network Observation System Subject: Re: [Observium] 30 minute poll issue
Look for other, newly added cron jobs. Discovery is only run once every 6 hours.
It's pretty difficult to make the poller believe that something is offline without network issues, as all it does to decide is a ping and an snmp get.
adam.
On 26/11/2012 08:14, Robert Williams wrote: Hi Guys,
Got a weird issue which has just started, seemingly by itself but I imagine there was a cause (I just don't know it yet!).
In short, every 30 minute the poller decides that approximately a third of all devices (92 in total) are 'Offline'. They then magically recover on the next poller interval.
The devices are not offline, and the Observium host does not loose connectivity (I've tested with numerous pings etc. during this predictable failure period).
Interestingly, the host on which Observium runs does record these interesting CPU and RAM metrics during that particular polling run:
[cid:image001.png@01CDCC0C.057AA510]
[cid:image002.png@01CDCC0C.057AA510]
Now, I'm guessing that there is maybe a more substantial 'discovery' run or similar every 30 minutes. For some reason, this more intensive run seems to be resulting in a load of devices going allegedly offline.
The problem started on Friday around 11pm and has repeated like clockwork since. We are running the latest SVN.
I'm a bit uncertain where to start with this one as although it's predictable I can't really see anything which would cause it to happen. Pointers for diagnosing further very welcome :)
Cheers as always!
Robert Williams
Custodian DataCentre
email: Robert@CustodianDC.commailto:Robert@CustodianDC.com
_______________________________________________
observium mailing list
observium@observium.orgmailto:observium@observium.org
http://postman.memetic.org/cgi-bin/mailman/listinfo/observium
_______________________________________________
observium mailing list
observium@observium.orgmailto:observium@observium.org
http://postman.memetic.org/cgi-bin/mailman/listinfo/observium
_______________________________________________
observium mailing list
observium@observium.orgmailto:observium@observium.org
http://postman.memetic.org/cgi-bin/mailman/listinfo/observium
{kind=link}
{kind=link}
Almost all recent changes have been web-interface related.
We did change the loop around the rrdtool binary, but that shouldn't affect polling.
Detecting up/down doesn't really have any prerequisites. It does an ICMP ping and a UDP snmpget. If either of those fail to return, and the host isn't already down, it changes the value in the database to down and skips the rest of the poll.
There is nothing really code-related that could cause the effects you're seeing, only the return packets failing to reach the PHP process in time. This kind of thing isn't even observed on very, very heavily loaded systems.
Is this a virtualised system?
adam.
On 26/11/2012 13:27, Robert Williams wrote:
Hi, well any ignoring you think I'm doing is certainly not the case -- you said to check for other cron jobs and I did. There aren't any (literally, this system has only Observium on it). I also checked for any processes running at the point of the 'host down' events as was also suggested; the only one is the poller / php process itself. Which takes more CPU on every 6^th poll, but nothing more interesting than that. If there were other suggestions then I'm really sorry I've obviously missed them (which is quite likely as I've noticed before some postings from this list have been dropped by our filtering system). Either way, I'm certainly not ignoring you, I think it would be a bit stupid to ignore any advice from the creator of the product which you are having trouble with :)
Always suspect the last change you made broke it -- so since there were five or six hosts added last week my initial suspicion was maybe the poller was running out of time. The higher number hosts failing, in order, suggested to me that (assuming it polls them in numerical order) again maybe it is running out of time before completing. This was slightly confirmed by removing hosts at random and suddenly the problem went away.
I'm just trying to fault-find at the same time as asking for pointers and I'm happy to check anything that anyone on here may suggest.
Incidentally I'm just deploying Job's poller-wrapper script which I've been meaning to do for a while but never got around to it. I'll know in 30 minutes or so if it's helped at all and I'll let you know.
In the meantime, please do let me know if I've missed or ignored something, as I've most certainly not intended to -- cheers!
*Robert Williams*
Custodian DataCentre
email: Robert@CustodianDC.com
*From:*observium-bounces@observium.org [mailto:observium-bounces@observium.org] *On Behalf Of *Adam Armstrong *Sent:* 26 November 2012 18:59 *To:* Observium Network Observation System *Subject:* Re: [Observium] 30 minute poll issue
You're looking in completely the wrong place, and you've totally ignored everything i've said, so I give up.
have fun.
On 26/11/2012 12:24, Robert Williams wrote:
Right -- I've disabled a few of the recent additions and each time I disable one the number of hosts which are 'down' decreases. Now, with 3 hosts disabled I only have 2 hosts which are failing. Also, the hosts which fail are always numbered sequentially and are always high-numbered, say above host ID 90. Is it possible the poller is simply running out of time? Can the time be extended? Either way, why only on exactly every 6 polls / 30 minutes? Weird... *Robert Williams* Custodian DataCentre email: Robert@CustodianDC.com <mailto:Robert@CustodianDC.com> *From:*observium-bounces@observium.org <mailto:observium-bounces@observium.org> [mailto:observium-bounces@observium.org] *On Behalf Of *Adam Armstrong *Sent:* 26 November 2012 16:58 *To:* Observium Network Observation System *Subject:* Re: [Observium] 30 minute poll issue Btw, when one single installation out of thousands starts doing something like this, it's almost never related to the code, and almost always related to the system it's installed on. adam. On 26/11/2012 10:38, Robert Williams wrote: Hi -- no other cron jobs on that box, it's purely running Observium and the only jobs are the poller itself and a selection of jobs which run at weekly or daily intervals for various system functions. There is also a weekly SVN pull for Observium :) As a test we have removed the most recently added device to see if that helps, but I could do with some way of recording what is happening on that particular poll. It's like clockwork but I can't see anything that would cause that on the network side, and everything definitely responds (from the Observium console) 100% during the poll itself. Cheers! *Robert Williams* Custodian DataCentre email: Robert@CustodianDC.com <mailto:Robert@CustodianDC.com> *From:*observium-bounces@observium.org <mailto:observium-bounces@observium.org> [mailto:observium-bounces@observium.org] *On Behalf Of *Adam Armstrong *Sent:* 26 November 2012 16:07 *To:* Observium Network Observation System *Subject:* Re: [Observium] 30 minute poll issue Look for other, newly added cron jobs. Discovery is only run once every 6 hours. It's pretty difficult to make the poller believe that something is offline without network issues, as all it does to decide is a ping and an snmp get. adam. On 26/11/2012 08:14, Robert Williams wrote: Hi Guys, Got a weird issue which has just started, seemingly by itself but I imagine there was a cause (I just don't know it yet!). In short, every 30 minute the poller decides that approximately a third of all devices (92 in total) are 'Offline'. They then magically recover on the next poller interval. The devices are not offline, and the Observium host does not loose connectivity (I've tested with numerous pings etc. during this predictable failure period). Interestingly, the host on which Observium runs does record these interesting CPU and RAM metrics during that particular polling run: Now, I'm guessing that there is maybe a more substantial 'discovery' run or similar every 30 minutes. For some reason, this more intensive run seems to be resulting in a load of devices going allegedly offline. The problem started on Friday around 11pm and has repeated like clockwork since. We are running the latest SVN. I'm a bit uncertain where to start with this one as although it's predictable I can't really see anything which would cause it to happen. Pointers for diagnosing further very welcome J Cheers as always! *Robert Williams* Custodian DataCentre email: Robert@CustodianDC.com <mailto:Robert@CustodianDC.com> _______________________________________________ observium mailing list observium@observium.org <mailto:observium@observium.org> http://postman.memetic.org/cgi-bin/mailman/listinfo/observium _______________________________________________ observium mailing list observium@observium.org <mailto:observium@observium.org> http://postman.memetic.org/cgi-bin/mailman/listinfo/observium _______________________________________________ observium mailing list observium@observium.org <mailto:observium@observium.org> http://postman.memetic.org/cgi-bin/mailman/listinfo/observium
observium mailing list observium@observium.org http://postman.memetic.org/cgi-bin/mailman/listinfo/observium
{kind=link}
{kind=link}
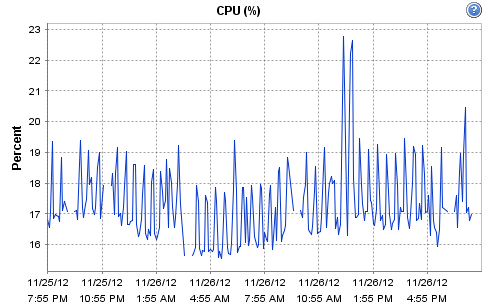
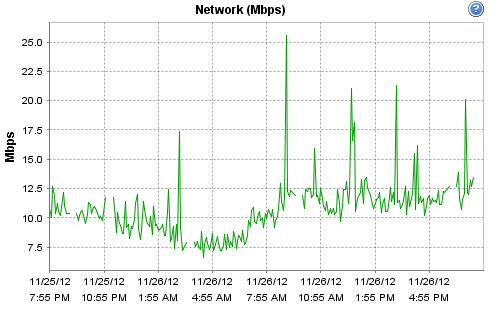
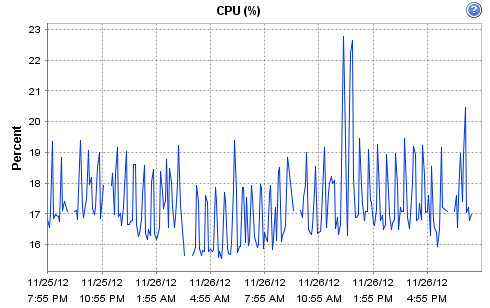
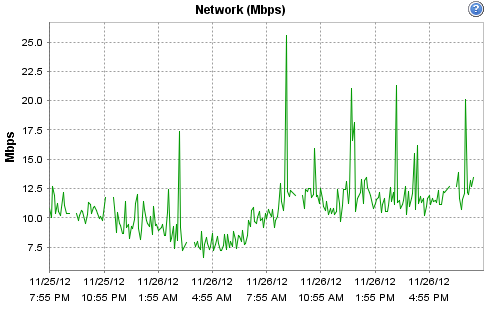
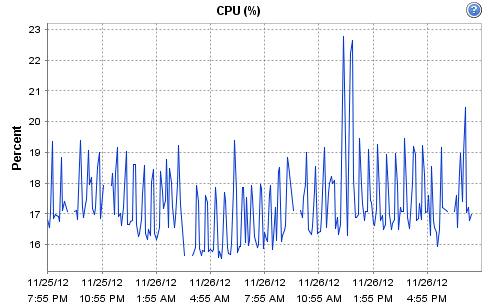
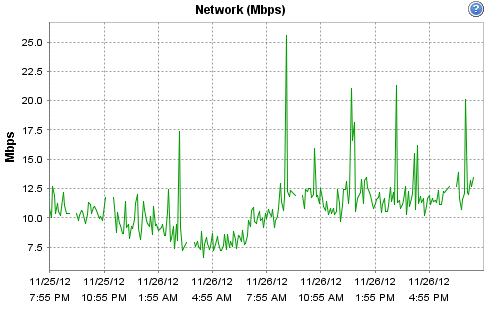
Hi - yes it is indeed virtualised, the host is a Dell R710 - 12 Cores @ 2.4GHz / 16GB according to ESX. It's running on an enterprise grade Kingston SSD, along with Cacti. The host is fairly low-load (it only runs a few monitoring systems and a couple of virtual routers). CPU and network load on the physical host for today are:
[cid:image001.png@01CDCC10.0821AC60]
[cid:image002.png@01CDCC10.0821AC60]
It has a 1GB NIC and I've already checked but over the last 4 hours it hasn't dropped a single ICMP ping to any of the 4 targets I've been continuously polling directly from the Observium VM. Three of the targets were repeatedly showing as down, until I suspended a few hosts on the total devices list. For what it's worth, the other monitoring instance on there (Cacti) has about 7,000 data sources and isn't missing a single one. It is on a one-minute polling interval and takes between 10 and 12 seconds to complete. Observium has also been flawless up until now.
Interestingly, at 19:10 I moved to the poller-wrapper and re-enabled the hosts that I had disabled. Now CPU usage during each poll is approx 2x and the duration of the polling event is now about 45 seconds according to the wrapper.
Since that change, I've not had a host go down? It could be coincidence, so I'm going to leave it overnight without making any other changes and see if by the morning it has started doing it again.
Out of curiosity - is it possible, with a single poller instance (i.e. what I had before) that should a host respond correctly to the first SNMP get / ping, but then take a very long time to respond to the rest of the polls (say 5 seconds per OID), that it could delay the polling process enough for it to run out of time before hitting all the targets? Thus declare the rest it missed as 'down' because it never got around to them?
I only ask because if this is possible then it could explain why adding more hosts could lead to this as there are a couple which I know are particularly slow to respond. Specifically they are hardware-integrated SNMP modules on systems which run tiny ARM chips and linux 2.4.21-rmk1. They are _slow_ to get their answers back, especially if two systems are concurrently polling them. If it isn't possible, then that's obviously off the mark, but the fact that the wrapper (appears) to have resolved it makes me wonder enough to ask :)
Cheers!
Robert Williams
Custodian DataCentre
email: Robert@CustodianDC.com
From: observium-bounces@observium.org [mailto:observium-bounces@observium.org] On Behalf Of Adam Armstrong Sent: 26 November 2012 19:49 To: Observium Network Observation System Subject: Re: [Observium] 30 minute poll issue
Almost all recent changes have been web-interface related.
We did change the loop around the rrdtool binary, but that shouldn't affect polling.
Detecting up/down doesn't really have any prerequisites. It does an ICMP ping and a UDP snmpget. If either of those fail to return, and the host isn't already down, it changes the value in the database to down and skips the rest of the poll.
There is nothing really code-related that could cause the effects you're seeing, only the return packets failing to reach the PHP process in time. This kind of thing isn't even observed on very, very heavily loaded systems.
Is this a virtualised system?
adam.
On 26/11/2012 13:27, Robert Williams wrote: Hi, well any ignoring you think I'm doing is certainly not the case - you said to check for other cron jobs and I did. There aren't any (literally, this system has only Observium on it). I also checked for any processes running at the point of the 'host down' events as was also suggested; the only one is the poller / php process itself. Which takes more CPU on every 6th poll, but nothing more interesting than that. If there were other suggestions then I'm really sorry I've obviously missed them (which is quite likely as I've noticed before some postings from this list have been dropped by our filtering system). Either way, I'm certainly not ignoring you, I think it would be a bit stupid to ignore any advice from the creator of the product which you are having trouble with :)
Always suspect the last change you made broke it - so since there were five or six hosts added last week my initial suspicion was maybe the poller was running out of time. The higher number hosts failing, in order, suggested to me that (assuming it polls them in numerical order) again maybe it is running out of time before completing. This was slightly confirmed by removing hosts at random and suddenly the problem went away.
I'm just trying to fault-find at the same time as asking for pointers and I'm happy to check anything that anyone on here may suggest.
Incidentally I'm just deploying Job's poller-wrapper script which I've been meaning to do for a while but never got around to it. I'll know in 30 minutes or so if it's helped at all and I'll let you know.
In the meantime, please do let me know if I've missed or ignored something, as I've most certainly not intended to - cheers!
Robert Williams
Custodian DataCentre
email: Robert@CustodianDC.commailto:Robert@CustodianDC.com
From: observium-bounces@observium.orgmailto:observium-bounces@observium.org [mailto:observium-bounces@observium.org] On Behalf Of Adam Armstrong Sent: 26 November 2012 18:59 To: Observium Network Observation System Subject: Re: [Observium] 30 minute poll issue
You're looking in completely the wrong place, and you've totally ignored everything i've said, so I give up.
have fun.
On 26/11/2012 12:24, Robert Williams wrote: Right - I've disabled a few of the recent additions and each time I disable one the number of hosts which are 'down' decreases. Now, with 3 hosts disabled I only have 2 hosts which are failing.
Also, the hosts which fail are always numbered sequentially and are always high-numbered, say above host ID 90.
Is it possible the poller is simply running out of time? Can the time be extended? Either way, why only on exactly every 6 polls / 30 minutes? Weird...
Robert Williams
Custodian DataCentre
email: Robert@CustodianDC.commailto:Robert@CustodianDC.com
From: observium-bounces@observium.orgmailto:observium-bounces@observium.org [mailto:observium-bounces@observium.org] On Behalf Of Adam Armstrong Sent: 26 November 2012 16:58 To: Observium Network Observation System Subject: Re: [Observium] 30 minute poll issue
Btw, when one single installation out of thousands starts doing something like this, it's almost never related to the code, and almost always related to the system it's installed on.
adam.
On 26/11/2012 10:38, Robert Williams wrote: Hi - no other cron jobs on that box, it's purely running Observium and the only jobs are the poller itself and a selection of jobs which run at weekly or daily intervals for various system functions. There is also a weekly SVN pull for Observium :)
As a test we have removed the most recently added device to see if that helps, but I could do with some way of recording what is happening on that particular poll. It's like clockwork but I can't see anything that would cause that on the network side, and everything definitely responds (from the Observium console) 100% during the poll itself.
Cheers!
Robert Williams
Custodian DataCentre
email: Robert@CustodianDC.commailto:Robert@CustodianDC.com
From: observium-bounces@observium.orgmailto:observium-bounces@observium.org [mailto:observium-bounces@observium.org] On Behalf Of Adam Armstrong Sent: 26 November 2012 16:07 To: Observium Network Observation System Subject: Re: [Observium] 30 minute poll issue
Look for other, newly added cron jobs. Discovery is only run once every 6 hours.
It's pretty difficult to make the poller believe that something is offline without network issues, as all it does to decide is a ping and an snmp get.
adam.
On 26/11/2012 08:14, Robert Williams wrote: Hi Guys,
Got a weird issue which has just started, seemingly by itself but I imagine there was a cause (I just don't know it yet!).
In short, every 30 minute the poller decides that approximately a third of all devices (92 in total) are 'Offline'. They then magically recover on the next poller interval.
The devices are not offline, and the Observium host does not loose connectivity (I've tested with numerous pings etc. during this predictable failure period).
Interestingly, the host on which Observium runs does record these interesting CPU and RAM metrics during that particular polling run:
[cid:image003.png@01CDCC10.0821AC60]
[cid:image004.png@01CDCC10.0821AC60]
Now, I'm guessing that there is maybe a more substantial 'discovery' run or similar every 30 minutes. For some reason, this more intensive run seems to be resulting in a load of devices going allegedly offline.
The problem started on Friday around 11pm and has repeated like clockwork since. We are running the latest SVN.
I'm a bit uncertain where to start with this one as although it's predictable I can't really see anything which would cause it to happen. Pointers for diagnosing further very welcome :)
Cheers as always!
Robert Williams
Custodian DataCentre
email: Robert@CustodianDC.commailto:Robert@CustodianDC.com
_______________________________________________
observium mailing list
observium@observium.orgmailto:observium@observium.org
http://postman.memetic.org/cgi-bin/mailman/listinfo/observium
_______________________________________________
observium mailing list
observium@observium.orgmailto:observium@observium.org
http://postman.memetic.org/cgi-bin/mailman/listinfo/observium
_______________________________________________
observium mailing list
observium@observium.orgmailto:observium@observium.org
http://postman.memetic.org/cgi-bin/mailman/listinfo/observium
_______________________________________________
observium mailing list
observium@observium.orgmailto:observium@observium.org
http://postman.memetic.org/cgi-bin/mailman/listinfo/observium
{kind=link}
{kind=link}
{kind=link}
{kind=link}
On 26/11/2012 14:09, Robert Williams wrote:
Hi -- yes it is indeed virtualised, the host is a Dell R710 - 12 Cores @ 2.4GHz / 16GB according to ESX. It's running on an enterprise grade Kingston SSD, along with Cacti. The host is fairly low-load (it only runs a few monitoring systems and a couple of virtual routers). CPU and network load on the physical host for today are:
It has a 1GB NIC and I've already checked but over the last 4 hours it hasn't dropped a single ICMP ping to any of the 4 targets I've been continuously polling directly from the Observium VM. Three of the targets were repeatedly showing as down, until I suspended a few hosts on the total devices list. For what it's worth, the other monitoring instance on there (Cacti) has about 7,000 data sources and isn't missing a single one. It is on a one-minute polling interval and takes between 10 and 12 seconds to complete. Observium has also been flawless up until now.
Interestingly, at 19:10 I moved to the poller-wrapper and re-enabled the hosts that I had disabled. Now CPU usage during each poll is approx 2x and the duration of the polling event is now about 45 seconds according to the wrapper.
Since that change, I've not had a host go down? It could be coincidence, so I'm going to leave it overnight without making any other changes and see if by the morning it has started doing it again.
Out of curiosity - is it possible, with a single poller instance (i.e. what I had before) that should a host respond correctly to the first SNMP get / ping, but then take a very long time to respond to the rest of the polls (say 5 seconds per OID), that it could delay the polling process enough for it to run out of time before hitting all the targets? Thus declare the rest it missed as 'down' because it never got around to them?
Nope, this isn't how the poller works, it's not smart enough to detect a "down" device during a polling run, it only does it at the very beginning.
The poller also doesn't have a fixed amount of time in which to run, it continues running until it's finished. It doesn't matter if it isn't finished before a new instance starts, because individual hosts will still be polled ~5 mins apart.
I only ask because if this is possible then it could explain why adding more hosts could lead to this as there are a couple which I know are particularly slow to respond. Specifically they are hardware-integrated SNMP modules on systems which run tiny ARM chips and linux 2.4.21-rmk1. They are _/slow/_ to get their answers back, especially if two systems are concurrently polling them. If it isn't possible, then that's obviously off the mark, but the fact that the wrapper (appears) to have resolved it makes me wonder enough to ask :)
It's possible that the additional devices shuffled the order in such a way that polling of the slower devices clashed with cacti and lead to device-down events. There are configuration variables to change the timeout and retries for SNMP.
If it's not that, the only thing that I can think of that is causing this is some I/O bottleneck, either disk I/O causing a knock-on effect elsewhere or a network I/O bottleneck. If it was anything in the code we'd have lots and lots of people complaining!
If it persists, you could try reverting the only change we made to code used by the poller, the RRD loop. Remove the "i++;" from the loop in the middle of includes/rrdtool.inc.php.
adam.
{kind=link}
{kind=link}
Hi - thanks for the additional detail, that rules out the poller from giving up. I still can't quite see what could be causing it then. I'm certainly not blaming a change the code itself, in fact it is almost certainly the result of the additional devices as it's been find until now and has never done this before. I just don't see why every 30 minutes it would clash with Cacti which runs every minute. Also, why would it make some hosts appear as down which are not the slow responding hosts. Plus why is it always the hosts above ID 90 which fail, the ones below that ID are 100% up.
Anyway, thus far it's been happier with the multi-threaded poller, although if it wasn't timing out on the poller before then I don't see why that's made any difference. I'm confident it's not network or disk i/o because both are monitored very closely and neither are anywhere near their limits. Some of the devices it polls are even attached to the same switch it is on and the SSD is a 60k write IOPS unit running only Cacti and Observium. Cacti finishes in around 12 seconds with the same devices (and about 500 more data sources with some of our custom scripts) so there is no way the devices are taking very long to answer the same questions to Observium. Occasionally there are those few special 'slow' devices, but they aren't the ones which show as down...bizzare...
Well, let's see if it stays stable overnight, thanks for your help!
Robert Williams
Custodian DataCentre
email: Robert@CustodianDC.com
From: observium-bounces@observium.org [mailto:observium-bounces@observium.org] On Behalf Of Adam Armstrong Sent: 26 November 2012 20:31 To: Observium Network Observation System Subject: Re: [Observium] 30 minute poll issue
On 26/11/2012 14:09, Robert Williams wrote: Hi - yes it is indeed virtualised, the host is a Dell R710 - 12 Cores @ 2.4GHz / 16GB according to ESX. It's running on an enterprise grade Kingston SSD, along with Cacti. The host is fairly low-load (it only runs a few monitoring systems and a couple of virtual routers). CPU and network load on the physical host for today are:
[cid:image001.png@01CDCC1A.15FD24E0]
[cid:image002.png@01CDCC1A.15FD24E0]
It has a 1GB NIC and I've already checked but over the last 4 hours it hasn't dropped a single ICMP ping to any of the 4 targets I've been continuously polling directly from the Observium VM. Three of the targets were repeatedly showing as down, until I suspended a few hosts on the total devices list. For what it's worth, the other monitoring instance on there (Cacti) has about 7,000 data sources and isn't missing a single one. It is on a one-minute polling interval and takes between 10 and 12 seconds to complete. Observium has also been flawless up until now.
Interestingly, at 19:10 I moved to the poller-wrapper and re-enabled the hosts that I had disabled. Now CPU usage during each poll is approx 2x and the duration of the polling event is now about 45 seconds according to the wrapper.
Since that change, I've not had a host go down? It could be coincidence, so I'm going to leave it overnight without making any other changes and see if by the morning it has started doing it again.
Out of curiosity - is it possible, with a single poller instance (i.e. what I had before) that should a host respond correctly to the first SNMP get / ping, but then take a very long time to respond to the rest of the polls (say 5 seconds per OID), that it could delay the polling process enough for it to run out of time before hitting all the targets? Thus declare the rest it missed as 'down' because it never got around to them?
Nope, this isn't how the poller works, it's not smart enough to detect a "down" device during a polling run, it only does it at the very beginning.
The poller also doesn't have a fixed amount of time in which to run, it continues running until it's finished. It doesn't matter if it isn't finished before a new instance starts, because individual hosts will still be polled ~5 mins apart.
I only ask because if this is possible then it could explain why adding more hosts could lead to this as there are a couple which I know are particularly slow to respond. Specifically they are hardware-integrated SNMP modules on systems which run tiny ARM chips and linux 2.4.21-rmk1. They are _slow_ to get their answers back, especially if two systems are concurrently polling them. If it isn't possible, then that's obviously off the mark, but the fact that the wrapper (appears) to have resolved it makes me wonder enough to ask :) It's possible that the additional devices shuffled the order in such a way that polling of the slower devices clashed with cacti and lead to device-down events. There are configuration variables to change the timeout and retries for SNMP.
If it's not that, the only thing that I can think of that is causing this is some I/O bottleneck, either disk I/O causing a knock-on effect elsewhere or a network I/O bottleneck. If it was anything in the code we'd have lots and lots of people complaining!
If it persists, you could try reverting the only change we made to code used by the poller, the RRD loop. Remove the "i++;" from the loop in the middle of includes/rrdtool.inc.php.
adam.
{kind=link}
{kind=link}
participants (3)
-
 Adam Armstrong
Adam Armstrong -
 Nikolay Shopik
Nikolay Shopik -
 Robert Williams
Robert Williams